在这篇博客,我使用 Pytorch 构建了一个 AlexNet 网络,通过 flower_data 数据集训练 AlexNet 识别各种花朵,然后我分别使用 pytorch 直接推理网络,以及使用 tvm 编译过后的模型推理网络,对比了两者的输出,以及运行的速度。
Github Page:https://github.com/LeiWang1999/AlexNetTVM
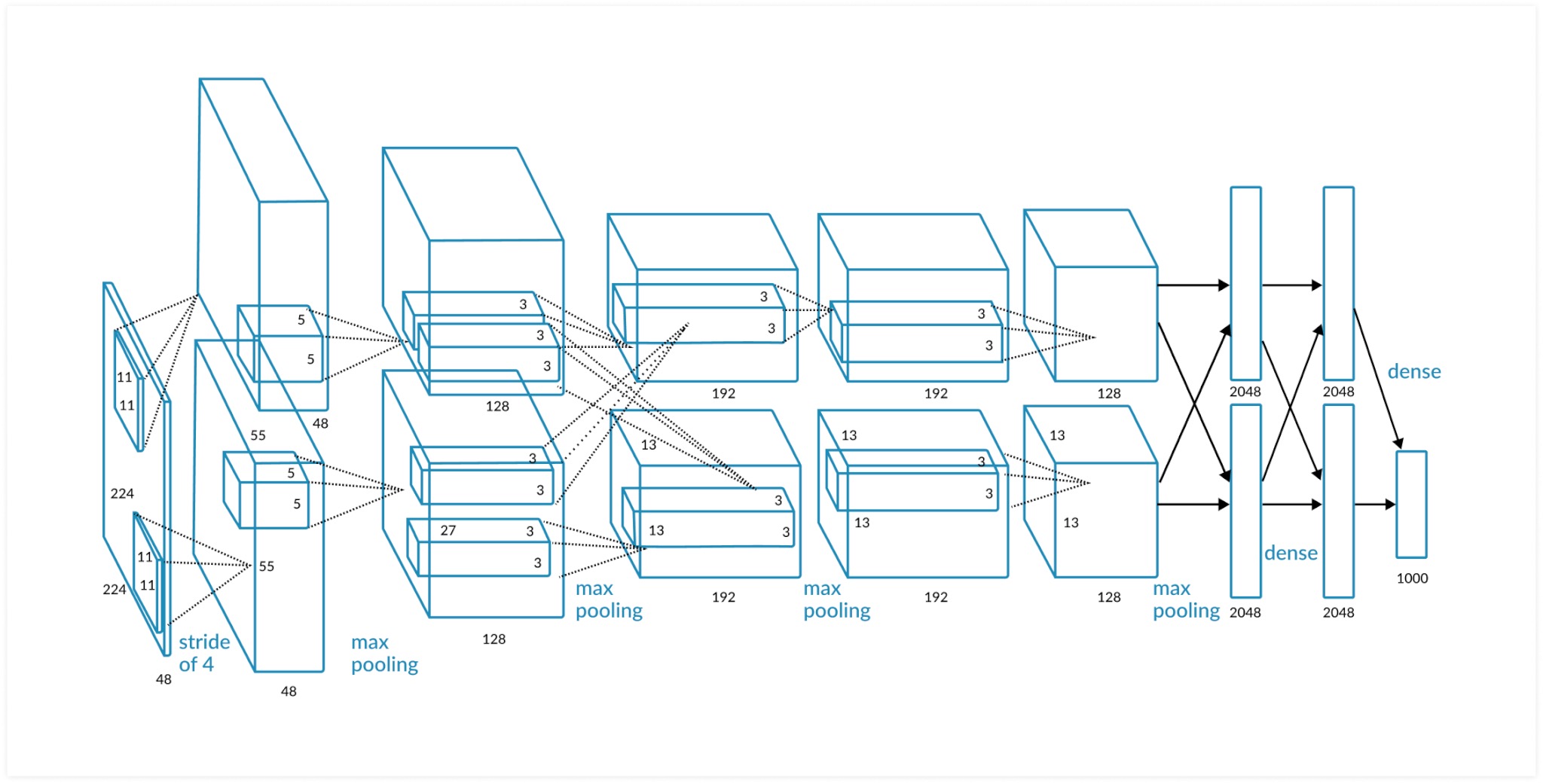
AlexNet brief Introduction
AlexNet 是 2012 年 ImageNet 竞赛冠军获得者 Hinton 和他的学生 Alex Krizhevsky 设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的 vgg,GoogLeNet。AlexNet 中包含了几个比较新的技术点,也首次在 CNN 中成功应用了 ReLU、Dropout 和 LRN 等 Trick。
有关网络的模型是咋样的,可以去读 Alex 的原论文,相比于现在的模型,AlexNet 的模型还是比较简单的。我比较推荐一个 B 站宝藏 UP 主的讲解视频,训练代码也是抄的他的。
这一小节主要就是为了凑字数,话说不会真的有人不知道 AlexNet 是啥吧?
训练 AlexNet
准备数据集
下载 flower_data: http://download.tensorflow.org/example_images/flower_photos.tgz
解压到工程文件夹,注意文件夹名字是 flower_data
运行”split_data.py”脚本自动将数据集划分成训练集 train 和验证集 val
运行 train.py 就会进行 AlexNet 的训练了,模型定义在 model.py 里。
训练完成后,取在 val 集上表现最好的 model 保存成文件,这里我用了两种保存方式。
torch.save(model.state_dict(), 'AlexNet_weights.pth')
torch.save(model, 'AlexNet.pth')有什么区别?
在 PyTorch 中,模型的可学习参数(model.parameters()可以访问的)state_dict 是一个简单的 Python 字典对象,每个层映射到其参数张量。只有具有可学习参数的层(卷积层,线性层等)和已注册的缓冲区(batchnorm 的 running_mean)才在模型的 state_dict 中具有条目。优化器对象(torch.optim)还具有 state_dict,其中包含有关优化器状态以及所用超参数的信息。由于 state_dict 对象是 Python 词典,因此可以轻松地保存,更新,更改和还原它们,从而为 PyTorch 模型和优化器增加了很多模块化。
直接保存整个模型是保存/加载过程使用最直观的语法,并且涉及最少的代码。以这种方式保存模型将使用 Python 的 pickle 模块保存整个模块。这种方法的缺点是序列化的数据绑定到特定的类,并且在保存模型时使用确切的目录结构。这样做的原因是因为 pickle 不会保存模型类本身。而是将其保存到包含类的文件的路径,该路径在加载时使用。
总之,我喜欢用第一种,限制条件是导入的时候要给出模型。
AlexNet 推理
两种推理方式,没什么要说的。需要注意的是 TVM 的 relay 前端,接受的不是普通的 torch.nn.Module 对象,而是 ScriptModules。转换函数在 pytorch 官方也给出了。
scripted_model = torch.jit.trace(model, img).eval()计时比较
start = time.perf_counter()
# runing code
elapsed = (time.perf_counter() - start)Pytorch 推理
Time used: 0.019670627999999857
tensor([-2.5184, 0.9804, -2.7127, 2.6251, -0.5793])
sunflowers 0.8036765456199646TVM 推理
Time used: 0.011482629000000522
tensor([0.0047, 0.1552, 0.0039, 0.8037, 0.0326])
sunflowers tensor(0.8037)速度果然提升了,但这个结果和我之前测的结果还不太一样,之前测的时候 TVM 的推理速度可能要快过 Pytorch 几十倍,也许是我记错了。。
Comments