最近在使用NNFusion的时候发现Codegen出来的FP16的网络在V100上的性能打不过FP32(甚至要慢一倍以上),但是理论上FP16应该要比FP32有两倍的性能收益才对(V100 Cuda Core的half precision的最大吞吐量是single的两倍,在s9234 的slides中看到直接使用half的情况下peak performance其实和single差不多,都是15Tops ,但是Cuda Core提供了half2类型,可一次做两个half类型的运算,这是half在CUDA Core上的收益来源;V100卡上的Tensor Core只支持FP16,利用好Tensor Core可以获得非常强的加速,A100卡上的Tensor Core增加更多的精度支持)。
建议阅读的文章:
聊聊 GPU 峰值计算能力
A100 Tensor Float 32 性能实测
拿nvprof测试了一下发现主要的性能瓶颈是:half卷积算子的实现速度要比single慢一倍,而这部分运算又占了总体运行时间的绝大部分。
CUDNN的卷积性能 NNFusion直接codegen出来的卷积算子默认使用CUDNN的实现,是CUDNN本身对卷积算子的时间不行,还是没有用好CUDNN呢?
注意到一篇2019年的论文,作者在V100上做了CUDNN_V7,CUDA_v9的卷积性能分析:Performance Evaluation of cuDNN Convolution Algorithms on NVIDIA Volta GPUs 。
这篇论文的结论是:
the filter size and the number of inputs are the most significant parameters when selecting a GPU convolution algorithm for 32-bit FP data. For 16-bit FP, leveraging specialized arithmetic units (NVIDIA Tensor Cores) is key to obtain the best performance.
在为32位FP数据选择GPU的卷积算法时,filter的大小和输入个数是最重要的参数。对于FP16运算,利用专门的算术单元(NVIDIA Tensor Cores)是获得最佳性能的关键。
CUDNN_V7的卷积使用Tensor Core的方法官方有给blog ,必须得对运算做专门的限制,比如需要指定特定的算法,kernel和input的通道数需要跟8对齐等,我在自己的实验环境里用V8,也有相似的限制(但是没翻到V8用Tensor Core的文档)。
测试你的应用程序是否使用了Tensor Core 猜测是CUDNN没有使用到Tensor Core,于是开始分析应用程序的Tensor Core使用率,这里我用了两种分析方法,一种是用nvprof,另一种是用dlprof。
使用nvprof nvprof的tensor_precision_fu_utilization这个metrics可以看到tensorcore的使用信息,可以参考Using Nsight Compute or Nvprof to Show Mixed Precision Use in Deep Learning Models ,他会吐出不同kernel对tensorcore的利用率,分为0-10十一个等级,如果是0就代表没有使用tensorcore。
宿主机上使用:
1 sudo nvprof --metrics tensor_precision_fu_utilization ./main_test
用sudo是因为想要获取tensor_precision_fu_utilization的metrics需要用到底层驱动的API,普通用户没有权限获取,会报如下的错误:
1 2 ==616== Warning: The user does not have permission to profile on the target device. See the following link for instructions to enable permissions and get more information: https://developer.nvidia.com/NVSOLN1000exit to flush profile data.
Nvidia官方提供的解决办法在:https://developer.nvidia.com/NVSOLN1000 ,需要先卸载驱动再在挂载驱动的过程中加个flag,但是我测试下来发现直接用sudo就可以。
容器内使用:
需要在起docker容器的时候给容器权限,否则无法使用nvprof拿到tensor core metrics: https://codeyarns.com/tech/2019-05-08-nvprof-in-nvidia-docker-permissions-warning.html
1 nvprof --metrics tensor_precision_fu_utilization ./main_test
测试一个没有使用tensor core的cudnn单层卷积:
1 2 3 4 5 6 Invocations Metric Name Metric Description Min Max Avg"Tesla V100-PCIE-16GB (0)" float , float , int=128, int=5, int=5, int=3, int=3, int=3, int=1, bool=0, bool=1, bool=1>(int, int, int, float const *, int, float *, float const *, kernel_conv_params, __int64, int, float , float , int, float const *, float const *, bool, int, int)float , float , int, __half const *, __half const *, bool, int, int)
这里的Idle为0代表没有使用tensor core。
测试一个使用了tensor core的cudnn单层卷积:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Invocations Metric Name Metric Description Min Max Avg"Tesla V100-PCIE-16GB (0)" float , float , int, __half const *, __half const *, bool, int, int)float , bool=1, bool=0, cudnnKernelDataType_t=0>(int, int, int, int, __half const *, __half*, float , float )float , bool=1, bool=0, cudnnKernelDataType_t=0>(int, int, int, int, __half const *, __half*, float , float )
关于如何在cudnn的卷积中使用tensor core,可以参考这一篇blog 。
分析nvprof的日志可以看到cutlass_tensorop_h884fprop_analytic_64x64_32x2这个kernel使用了tensor core,但是使用率也很低,是Low(1)。
查看tensorrt过程中
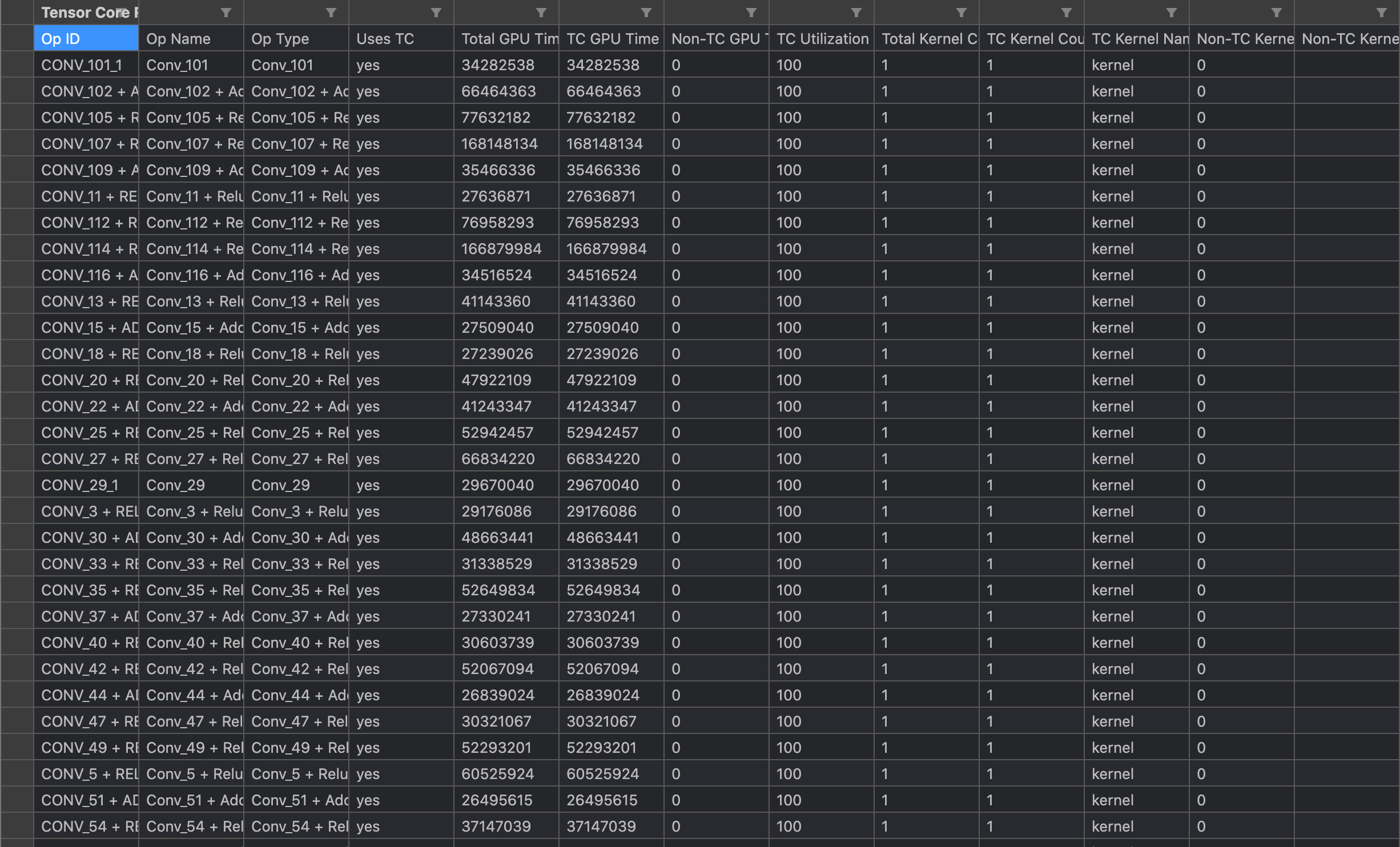
使用dlprof 实际测试的过程中发现使用nvprof测tensor core metrics的时候会影响程序运行的时间,例如原来的一次推理只需要运行6ms,加上了tensor_precision_fu_utilization 这个metrics之后,就变成了200ms左右才能完成一次推理,而为了测benchmark,我使用了5次warm_up和100次loop,时间还是很长的,而且nvprof拿到的信息也比较少,相比之下dlprof拿到的信息更加全面,不会影响程序的运行时间,输出也是的也是csv格式,更胜一步的是可以用tensorboard打开,这样方便在没有图形界面的情况下也能用网页端可视化查看资源:
1 dlprof --force=true --reports=all --mode=simple ./testCudNNConv
执行该命令之后,会在当下前目录下生成若干文件:
1 2 3 4 5 6 7 8 9 10 -rw-r--r-- 1 root root 622 May 31 15:48 dlprof_detailed.csv
其中summary可以看到总情况,tensor_core可以看到使用和没有使用tensor_core的kernel数量。
同样来看在没有使用tensorcore的单层卷积上,tensorcore的使用情况:
1 2 3 cat dlprof_tensor_core.csv
再看使用tensorcore的单层卷积上,tensorcore的使用情况:
1 2 3 4 cat dlprof_tensor_core.csv"SIMPLE_MODE_GLOBAL_NODE_OP_TYPE_1" ,"simple_mode_global_node_name" ,simple_mode_global_node_op_type,yes ,6583335,12063,6571272,0.2,17,1,"Kernel" ,16,"computeOffsetsKernel, explicit_convolve_sgemm, fft1d_c2r_32, fft1d_r2c_32, fft2d_c2r_64x64, fft2d_r2c_64x64, flip_filter, gemv2T_kernel_val, im2col4d_kernel, implicit_convolve_hhgemm, implicit_convolve_sgemm, nchwToNhwcKernel, nhwcToNchwKernel, transpose_readWrite_alignment_kernel, volta_gcgemm_32x32_nt, volta_scudnn_128x32_relu_medium_nn_v1"
只有一个kernel使用了tensor core,和nvprof的报告一致,但是kernel name却变成了kernel,没有nvprof的清晰..
但是这个工具测试tensorrt等一些框架就能得到很好的结果,例如测试一下tensorrt的resnet50,tensor core的利用率都打满了:
未完待续..
Comments