链接直达

之前回答某个知乎问题的时候简单描述了一下为什么通过加padding的方式可以解bank conflict:
https://www.zhihu.com/question/565420155
当时我画了这样一个图片:
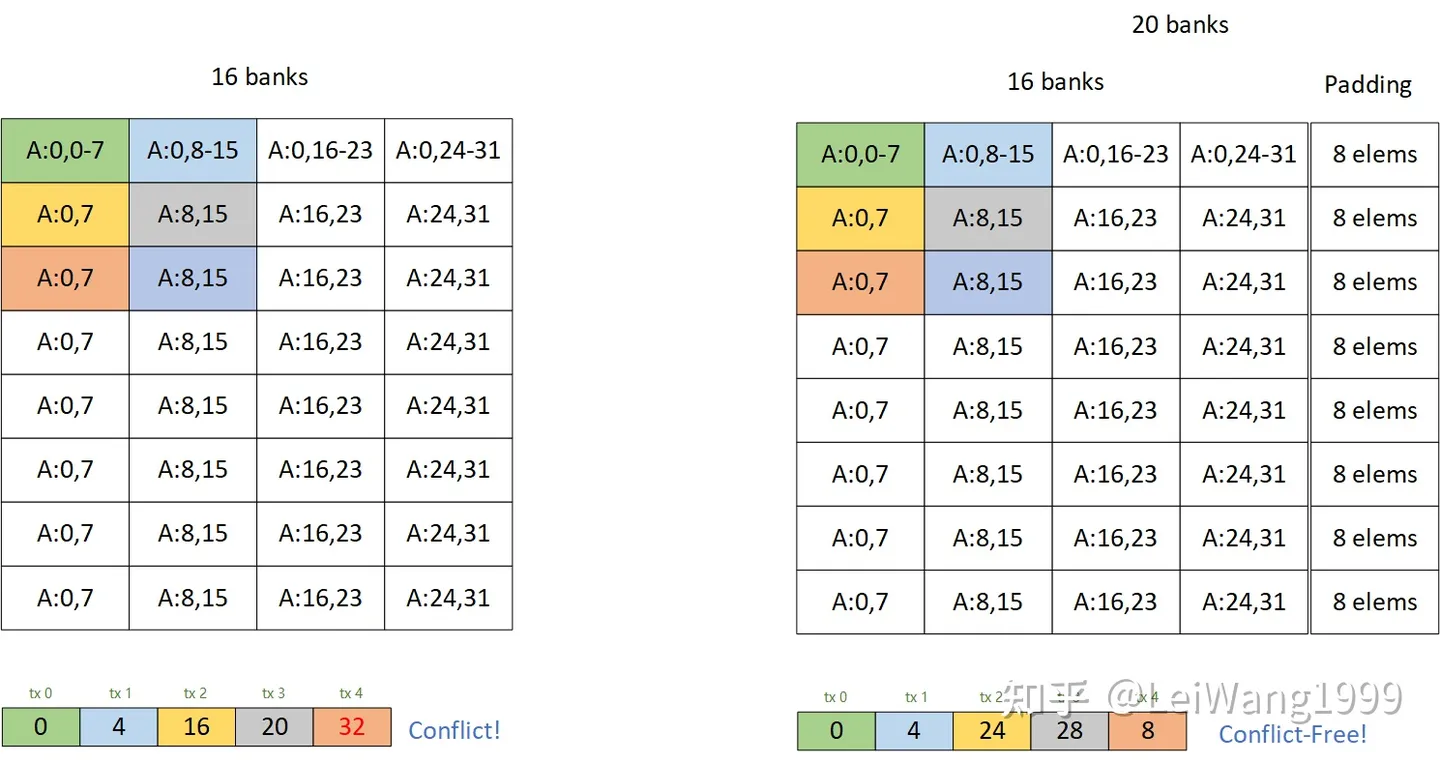
有一些同学还是不理解为什么这种方式可以解掉bank conflict,再加上我搜一搜也没发现有人讲清楚过这件事情。这篇文章以利用tensor core的矩阵乘法为例,较详细地分析一下解conflict的方法,同样我们选择一个最典型的cutlass tile 128x256x32 的 float16 的tile,用来说明问题,在最后,我会提供一份复现的代码,由Tensor IR实现,方便实现各种Tile(虽然我觉得加pad的性能并不能足够到sota。
回答知乎提问:https://www.zhihu.com/question/565420155
最近正好研究了一下这个schedule,顺便简单总结一下,官方给的文档介绍确实比较抽象: https://tvm.apache.org/docs/reference/api/python/tir.html
题主困惑的应该是factor和offset是什么意思,为什么这样能够解决shared memory bank conflict?
第一个问题,可以看看代码,首先是底层的实现(https://github.com/apache/tvm/blob/HEAD/src/tir/transforms/storage_flatten.cc#L480-L481):
PrimExpr stride = make_const(shape[first_dim].dtype(), 1);
for (size_t i = shape.size(); i != 0; --i) {
size_t dim = i - 1;
if (dim < avec.size() && avec[dim].align_factor != 0) {
PrimExpr factor = make_const(stride.dtype(), avec[dim].align_factor);
PrimExpr offset = make_const(stride.dtype(), avec[dim].align_offset);
stride = stride + indexmod(factor + offset - indexmod(stride, factor), factor);
stride = bound_analyzer_->Simplify(stride);
}
rstrides.push_back(stride);
stride = stride * shape[dim];
}在之前的两篇文章中,我们分别用TVM的Tensor Expression与TIR Script完成了在Nvidia Cuda Core上的高效的FP32 矩阵乘法,3090-24GB的各种精度在Cuda Core和Tensor Core上的Peak TFLOPS如下表所示:
| 3090-24GB | FP32 | FP16 | BF16 | INT32 | INT8 | INT4 |
|---|---|---|---|---|---|---|
| Cuda Core | 35.6 | 35.6 | 35.6 | 17.8 | 71.2 | \ |
| Tensor Core | \ | 142 / 284* | 142 / 284* | \ | 284 / 568* | 568 / 1136* |
有意思的是,3090上,FP16的Peak Peformance和FP32是一样的,这一点比较特殊,是因为架构上的改动,一般而言fp16的性能都会是fp32的两倍或者四倍,这个主要是因为20系的gpu把fp32和int32的Cuda Core分开了,从而能同时进行fp32和int32的计算,30系把int32的core又就加上了fp32的计算单元,所以fp32的计算能力翻倍,而cutlass下的16384的gemm。
按照3090上的硬件单元分类,我们还可以探索一些有意思的加速,比如在CUDA Core上使用SIMD指令(DP4A,HFMA2来优化int8、half的性能,
上一篇文章中讲到如何利用cutlass优化gemm的思路,使用tvm tensor expression来实现一个高效的矩阵乘法,这里再探索一下直接从TIR Script把这个东西复现一下,对比一下两者的异同。
TensorIR 今年7月再arxiv上放了一篇preprint,感兴趣的读者可以自行阅读:https://arxiv.org/abs/2207.04296
不过写这篇文章的时候,tvm上游(main)分支的tir与paper里还不是一样,siyuan他们另做了许多改进,估计要等paper中了才会被合并到上游(貌似是在投ASPLOS?所以这里还是以tvm上我们可以实际操作的TensorIR Script为例子,优化的思路则不多讲解,和之前的tensor expression是一样的。
PS: 感觉TIR Script的设计和写法更贴近GPU,比tensor expression更抽象,有亿点点摸不着头脑,不过也比直接从tensor ir来构建一个dag要舒服地多,虽然通过自己瞎理解与实验加上在论坛交流了一下,也算是都摸出来怎么实现,但我相信应该还会有更优雅的写法。
这里记录的是我想从tvm的tensor expression出发,参考一下cutlass efficient gemm的思路,一步一步优化一下GEMM的一些思考和碎碎念,目的是为了理解cutlass优化gemm的思路。
我们使用CUTLASS Profiler来运行一个gemm的运算,并用nsight compute dump下来其运行过程中的一些情况,可以拿到他的一些信息,如grid的大小与block的大小等。比如对于16384的float32类型数据的gemm,cutlass的grid size是(512, 16, 1)-> 8192个block, block size是(256,1,1),一共是2,097,152个线程,因为最后产生C的大小是(16384,16384),所以平均每个thread需要产生128个C的元素,结合这些参数的信息,使用tvm的te进行schedule(其实可以试试tensor ir),最后成功打到了和cublas,cutlass相近的性能。
测试GPU: rtx 3090 24GB
CUDA Version: 11.1
TVM Version: 10.0
Update your browser to view this website correctly. Update my browser now