前言
在之前的文章里笔者已经记述了怎样在FPGA上映射由英伟达开源的加速器NVDLA。但是NVDLA的官方发布的工具链很弱,只能端到端地运行极为简单的分类网络,而现在在绝大部分的深度神经网络应用里分类往往只是其中一小部分。例如我现在想利用加速器去运行yolo,但其中有许多加速器并不支持的算子,加速器支持的convolution、pooling、relu等等算子最好都要用加速器运行,而那些不支持的算子则需要Fallback到CPU去运行。
这片文章要介绍的是笔者利用Open AI Lab开源的边缘设备推理框架Tengine,为NVDLA打造一套新的工具链!

有意思的是,对于这件事近年来一些机构也基本上在可能的方向上有过尝试,例如:
- 台湾工研院的做法是硬刚NVDLA的寄存器配置,将yolov1-tiny之中可以使用加速器运行的层单独提出来并且量化,手动根据加速器需要的摆放格式放到内存,然后通过配置寄存器的方法完成加速器侧的推理,之后拿到数据之后用cpu算其他的layer。这种原始的方法部署需要对硬件理解的极为深刻,显然是一个非常懂硬件的一开始能够想到的可行方案。但我想一个人没有一两个月是完不成一个网络的部署的,而如果需要推理的目标网络换成另一个则需要做太多的重复工作。
- NVIDIA 官方与 Sifive 合作有介绍过一个firesim-nvdla的项目。他们在FPGA云服务器平台上面跑了一个RiscV+NVDLA。并且魔改了darknet,利用内部工具将yolov3中能够用dla运行的子图提取出来生成了Loadable文件,成功运行了yolov3,并且在large配置下yolov3可以到7帧。但是工具链是不开源的,并且局限在了darknet这个框架。
- 台湾的一家公司Skymizer则野心在制作一套全新的编译器,叫做ONNC。与官方的编译器只能接受caffe的模型不同,ONNC的前端接受的是ONNX模型。可惜的是这家公司开源的编译器也只能跑分类网络并且只能支持full配置,而且无法完成量化。但是其商业版本发布的内容来看支持的算子也很少,并且也只能跑yolov1-tiny,自己Custom也很麻烦因为CPU的算子也需要修改Runtime的代码去实现。在我的调研里发现,其商业版授权更是高达一年两百多万人名币!起初我以为他们看我是大陆人想宰我,结果认识几个台湾朋友也都反映是这个价格。一些初创公司的第一版加速器设计参考NVDLA,想必也为了短时间内度过难关、寻求应用而不得已花了不少钱购买授权吧。
这反映出来一个加速器设计完成之后的通病,缺少工具链的支持。一个大的公司可以单独成立一个部门,投入不少的人力为自己的加速器设计一套独有的工具链,但DLA不支持的算子数量可以高达近百个,实现他们不仅是个体力活,并且实现的过程还需要考虑到在不同设备上的运行效率。其次,还要具备强的模型接受能力,一般DL加速器支持INT8的较多,这又要求支持量化,又要能够自动的将计算图中的算子做切分,可以用DLA运行的调度DLA运行、不可以用DLA运行的Fallback到CPU去跑。
以上的种种问题对于一个小的团体来说,许多能在开源社区得到解决,而Tengine就是这样一个框架。并且为了与上面的几种方案对比(主要是卷一卷onnc),本篇文章也会利用 Tengine 演示一下如何利用完成模型的转换、量化,调度DLA跑一个yolox-nano网络!
一、NVDLA 与 Tengine 简介
应该少有读者会同时了解这两个框架,先简单介绍一下两者。
NVDLA (NVIDIA Deep Learning Accelerator) 是什么?
NVDLA 是英伟达于2017年开源出来的深度学习加速器框架,他的官方repo在这里。可惜的是,这个项目被开源出来一年后就草草停止维护了,留下了开发到一半突然停工的代码。NVDLA的核心是MAC阵列、其有若干个处理单元来决定MAC阵列的调度与运算:
- Convolution Core – optimized high-performance convolution engine.
- Single Data Processor – single-point lookup engine for activation functions.
- Planar Data Processor – planar averaging engine for pooling.
- Channel Data Processor – multi-channel averaging engine for advanced normalization functions.
- Dedicated Memory and Data Reshape Engines – memory-to-memory transformation acceleration for tensor reshape and copy operations.
并且这些处理单元都暴露出了一组可配置寄存器接口。
前文中提到他软件设计工具链的缺陷,主要是其Compiler、Runtime的程序写的非常乱,很难自己定制和增加功能,但是内核驱动代码写的很棒,有很多的参考价值。
硬件这部分,RTL代码生成我也不是很懂为何要使用如此多的工具链去搭建tmake,利用C语言的宏来处理字符串决定哪些模块应该生成,哪些模块不应该生成,而不是用 Verilog 内部的宏定义完成这部分工作。其次,其发布时间是2017年,那么实际的研发时间应该在2015年到2016年,其中的很多设计也正是借鉴的寒武纪最初的 DianNao、DaDianNao结构。而现在,不说寒武纪已经迭代了好几个版本并且上市了,而在这之后的一些研究,例如eyeriss系列、以及一些围绕着数据复用做出来的工作,NVDLA当时的设计肯定是没有考虑到的,所以其性能肯定不如当下的商用加速器。(话说能商用肯定搞钱去了,干嘛开源给大家玩
虽然看起来NVDLA的缺点很多,但其仍然极具学习价值!
NVDLA自上而下十分规范,其硬件设计是一个较为完整的体系结构。有寄存器接口,有PE阵列、有多级缓存设计,软件设计包括驱动程序,主机上的 Compiler、设备上的驱动程序与 Runtime等等。在一些学术论文里往往是关键的部分,比如作者的设计里 Runtime 做了哪些事,PE阵列是如何优化,缓存如何设计,但他们的设计细节又大多不会公开,基本无法通过看论文的方式复现。一个刚开始科研的小白看到了一篇论文,认为其有更好的设计方案,但是他拿什么去验证呢?NVDLA就可以作为一个典型的参考设计。NVDLA里,上述的这些单元都是实实在在的代码,研究价值还是极高的,在这里需要感谢英伟达的开源工作。
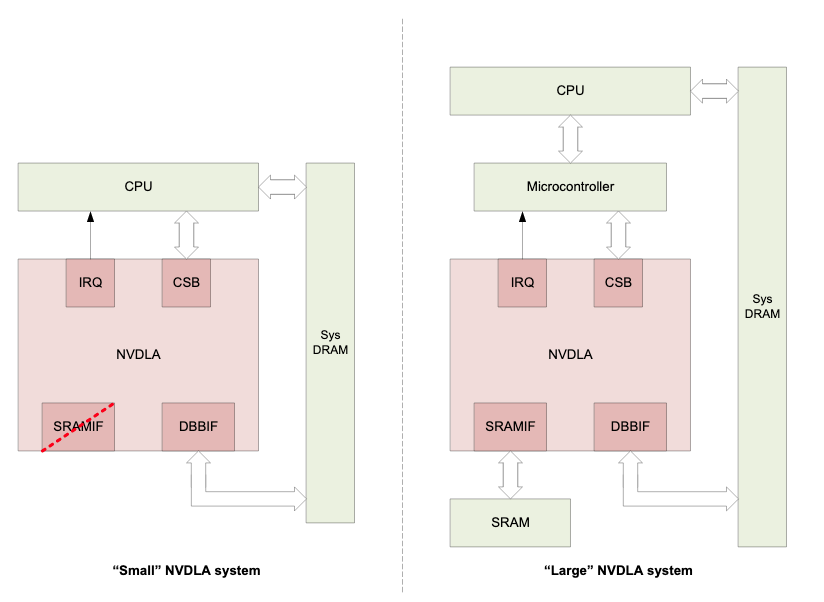
NVDLA 的硬件是可以配置的,比较典型的有full、large、media、small这几个版本,修改spec即可。本文使用的是其最小的small配置完成设计,一些算子其实是无法实现的,读者可以自行调整设计。
例如,在small的spec文件里:
1 | |
表示PE阵列的大小为8*8,而NVDLA的硬件最大的可以配置为32*32。
1 | |
表示Small没有使能查找表,导致只可以支持Relu这一种激活函数。
1 | |
表示Small没有使能RUBIK引擎,RUBIK在DLA里的作业是做数据重排,如此不可以支持反卷积等op的实现。
1 | |
表示没有使能Global Sram作为片上的高速缓存。
怎样部署 NVDLA 到自己的 FPGA 芯片上
本设计没有使用到任何外设,所以跟开发板无关,跟芯片有关。NVDLA 对 LUT 的资源要求较高,一般的器件只需要保证 LUT 的数目大于八万就可以部署small了。
https://zhuanlan.zhihu.com/p/378202360
这篇文章针对的是 ZYNQ 7000、ZYNQ MPSOC 器件,对于这些器件,可以参照我的教程使用 Xilinx 的 petalinux 制作 Linux 挂载驱动程序。对于别的器件,就需要使用buildroot这些第三方工具了。
从现有的经验来看,在我的repo的issue里有位老哥在Intel的FPGA上也完成了驱动和Runtime的移植(真的🐂)。如果是纯逻辑资源的器件,不妨试试chipyard,可以烧写一个riscv+nvdla进去,sifive也提供了非常简单的生成tutorial。
而如果你使用的是和笔者一样的ZCU102-rev-1.1,可以直接联系我我把SD卡的Image拷贝给你(或者之后会放到云盘上供大家下载。
上板成功之后,我建议换成 Ubuntu 的文件系统,怎样更换请看这篇文章:
https://zhuanlan.zhihu.com/p/392974835
而之后为了方便大家开发与调试,我将开发板通过以太网桥接到了自己的开发机器上,完成了开发板通过主机的wifi访问互联网,已经有了Windows、Ubuntu、MAC三个版本的解决方案,非常舒服:
https://zhuanlan.zhihu.com/p/378814739
我是在ZCU102上部署的NVDLA,除了FPGA资源以外还有一个四核的A53处理器。

为什么选择 Tengine
Tengine(不是阿里云那个Tengine),是由Open AI Lab开源的面向边缘设备推理的Runtime框架。在考虑Tengine之前,我也考虑过对接另一个推理框架TVM,但是TVM已经有一个开源的FPGA加速器后端VTA,并且TVM没有Tengine轻量(在之前逛TVM的社区里也有人想把TVM与NVDLA对接,但一直没有下文。而Tengine的后端对接过程使人感到舒适,下面是Tengine的architecture,看右下角的OpenDLA,就是已经有NVDLA的支持啦!
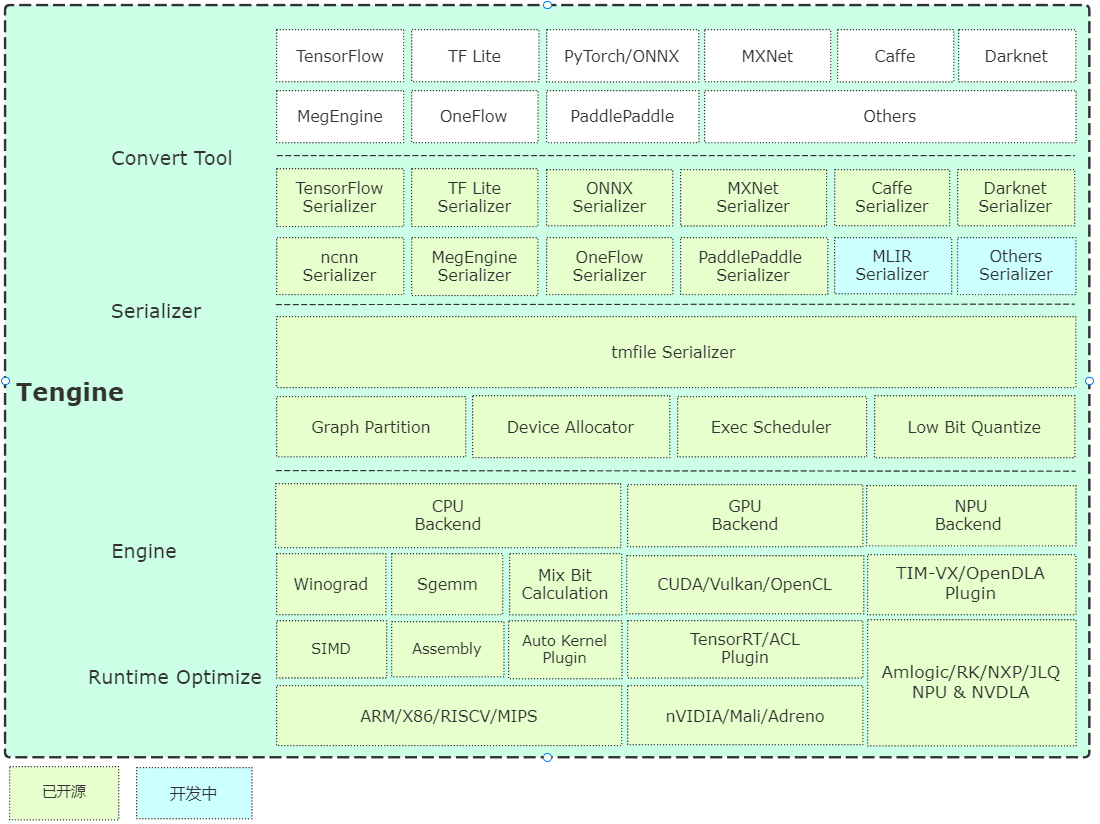
在前端的模型转换部分,可以把各大主流的训练框架训练出来的模型转化到Tengine的tmfile格式,也包括了在前言里提到的Caffe与ONNX,格局打开!在模型转化的时候,DLA可以吃到Tengine做的一些图优化,如果对接DLA后端在模型转化的时候需要把fuse_conv_relu_common关掉,因为现在还不支持conv和relu合并的op实现,这在之后重构IR的时候会支持的。
1 | |
模型的量化,Tengine也有现成的工具实现PTQ(Post Training Quantization Dynamic, 动态离线量化),并且与TensorRT的量化原理一致,用起来也更方便,不用像tensorrt那样手撸一堆代码,并且量化之后的scale,weight都会保存到生成的tmfile里,在推理的时候可以从ir中拿到量化的数据,包括量化完成的权重和偏置,以及每一层的scale。
与其他边缘设备推理框架的不同,Tengine的架构设计考虑到了对NPU的支持。在Tengine架构图的右下角出现的TIM-VX是一款NPU,而Tengine将这部分对接的代码开源,给本工作的设计提供了很多参考。Tengine针对这种异构体系结构的存在,存在一个特别关键的机制–自动切图。
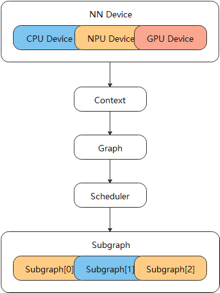
Tengine会根据后端的Device支持算子的情况,将一个Graph切分成若干个Subgraph。对于一个Device,只需要关心这个subgraph如何实现就好,因为你拿到的Graph里一定都是自己支持的算子。
例如,对于一个典型的Lenet5网络:
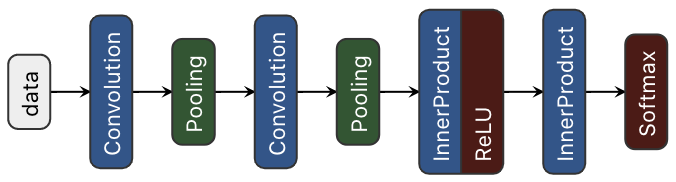
NVDLA不支持Softmax,那么Tengine在知道要使用NVDLA来做推理的情况下就会自动将原来的计算图切分为两个子图,第一个子图不包括Softmax,那么在DLA看来就是一个最后一层是FullyConnect的网络,第二个子图只有Softmax这一个节点,交给CPU运行。
不过,闲来大佬曾经说过:一个有经验的部署玩家在实际的部署过程中如果碰到最后一层Softmax,因为不影响分布就会直接去掉。
Tengine还有许多别的优点,在下一章慢慢介绍。
二、NVDLA后端对接代码走读
在这一小节,我将介绍一下笔者进行后端对接的流程。而这个过程中的很多细节可以去看一下OpenAILab的后端对接公开课,由闲来大佬主讲:
https://www.bilibili.com/video/BV1dM4y1P7oM
本文的所有代码基本上都在Tengine的source/device/opendla下:
1 | |
include和lib文件夹都可以Follow写在官方仓库里的教程,这里贴一个大概的流程:
首先,这里演示的整个编译的过程都在开发板卡上运行,否则需要交叉编译;例子都是以root的身份来运行的;如何使用开发板连网可以参考这篇文章。
2.1 对接思路简介
在对接之前,先讲解一下原来的NVDLA的软件栈是如何工作的,主要分为三个部分:

2.1.1 Compiler
在三个部分里,Compiler的代码数量是最多的,但却也是最需要我们重构的。NVDLA的编译器前端可以接受Caffe的模型,在内部会通过Parser转化为一个较为通用的 Network 对象,接着 Network 会被转化成 CanonicalAST, 接着 CanonicalAST又会被转化成EngineAST,EngineAST就是整个编译阶段最核心的IR。
例如,下图是我绘制的Lenet5的两个AST的结构,Canonical是通用的,所以该语法树就是一个很简单通用的结构,而EngineAST则每一个Node都被映射到硬件的单元,例如原来CanonicalAST里的Convolution Node会被应设为ConvlutionOPNode和SDPBiasOPNode两个节点,bias、weight和input也被从Node里抽离出来,然后,编译器会有很多PASS来针对EngineAST来工作,比如量化、比如简单的merge;等到所有的Pass都走完,最后得到的IR会被emit成为需要给Runtime的数据,以Flatbuffer序列化协议来组织,最后生成一个Loadable文件,交给Runtime做推理。
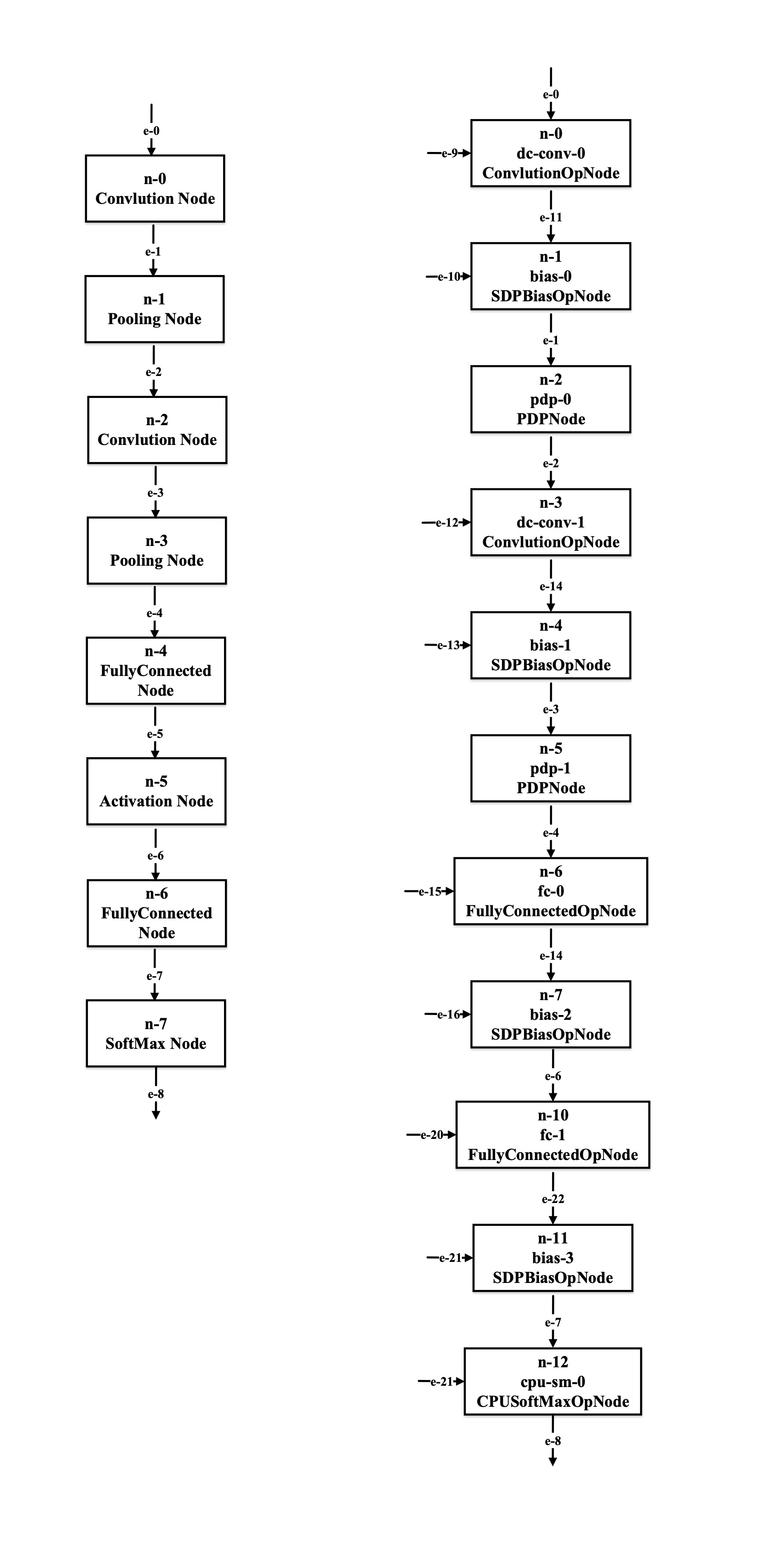
那么,如何对接呢?我在第一版使用官方的语法树来完成任务,于是在下文中进行编译的时候是把官方的core代码做成了lib进行链接,调用里面的 Function;另一方面,我想学习一下他的IR是怎么设计的,于是不从Network这么高的层次下手(当然这也导致无法很方便的做到OP的拼接,但也无所谓,反正要重构的);然后就是决定接入CanonicalAST还是EngineAST了,因为是调用的官方提供的函数来构建Graph,所以EngineAST的创建过于依赖CanonicalGraph,于是笔者选择把Tengine提供给后端的ir_graph接入CanonicalAST,然后转成EngineAST,所有的Pass仍然使用NVDLA的编译器提供的函数来作业。
2.1.2 Runtime
Runtime 的代码量不大,首先是需要将Compiler生成的Loadable进行反序列化,然后为输入输出tensor开辟内存,将输入的Tensor填充数据,递交任务给nvdla,拿到数据。我简化了一些流程:
Compiler和Runtime对接的时候原先需要由Compiler离线序列化生成Loadable文件,再由Runtime反序列化,我将这个步骤去除,data直接导入给Runtime:
1
2
3
4
5
6
7
8
9
10
11
12this->loadable.priv()->getSerializedDataSize(&loadableSize);
if(!loadableSize){
fprintf(stderr, "No Loadable Generated. \n");
return -1;
}
NvU8 * buffer = (NvU8 *)NvDlaAlloc(loadableSize);
if (buffer == NULL) {
fprintf(stderr, "Failed to allocate buffer for loadable. \n");
return -1;
}
// deserialize Loadable image
this->runtime->load(buffer, 0);当然要是需要生成Loadable,也是可以支持的,
export TG_ODLA_DEBUG_DATA=1可以生成Loadable:1
2
3
4
5NvDlaFileHandle file = 0;
std::string fileName = std::string(this->profile->getName()) + ".nvdla";
fprintf(stdout, "Dump loadable data to : %s . \n", fileName.c_str());
NvDlaFopen(fileName.c_str(), NVDLA_OPEN_WRITE, &file);
NvDlaFwrite(file, buffer, loadableSize);Runtime发送的Task其实又分为两个类别,Emulator和DLA,Emulator是完成CPU作业的,当然官方的Runtime也就只支持Softmax和Scale这两个CPU实现而已,这部分的初始化和注销在执行阶段占用了太多时间,因为现在CPU的Fallback工作都交给Tengine来完成,所以笔者把这部分代码去除了。
设计方案的折中,前文提到过了,是直接从CanonicalAST开始对接。
2.1.3 Kernel Driver
即opendla.ko,内核驱动代码负责根据Runtime递交的task完成具体的寄存器配置,调用DMA来进行数据搬移,处理中断信号等,相较于官方的文档在这部分代码里的寄存器配置方法更加清晰,例如这部分代码就配置了卷积的输出chw信息,寄存器的配置顺序看起来可比官方的手册要舒服:
1 | |
2.1.4 需要实现的函数:
Tengine的架构做的很好,对接一个后端的一部分工作就是反复套娃,抄抄其他后端的代码,然后改改名字。自己需要实现的大概是以下三个函数,以及创建一个后端Engine对象,这部分内容分别在odla_executor.hpp、odla_executor.cc里。
1 | |
从函数名可以看出他们执行的时间,在实际运行的时候顺序如下:prerun用来初始化数据,完成对接,优化等等,执行一次;prerun执行完了之后,run来塞输入数据,拿到输出数据,可以执行多次;在程序的最后,postrun用来free数据。
那么如果有多个子图,怎样来运行呢?一开始我也对此很迷惑(但这个步骤完全不需要后端对接人员care,Tengine会自己创建多个Engine实例,管理他们。
如何定义支持哪些op?
在odla_limit.hpp里完成注册,将后端能够支持的op取消注释(Tengine这里定义算子刚好有100个!):
1 | |
然后在odla_device.cc里会把支持的op与不支持的op分到两个vector里,由Tengine根据该信息完成切图,而每个具体op的实现在op文件夹里可以找到。
2.2 拉取代码
这里贴一下如何编译, 具体可以参考Tengine的文档,已经提交PR上去了。
2.1.1 拉取 ZYNQ-NVDLA
1 | |
2.1.2 拉取 Tengine-Lite
1 | |
2.3 Tengine-Lite 集成编译 opendla
Tengine-Lite 目前只支持一种 opendla 的集成编译方法,即编译opendla的软件支持,首先生成.so文件,而在Tengine编译opendla后端的时候进行链接。
其他的方案,例如在Tengine编译的过程中连同opendla的编译器和运行时的源代码一起编译,由于代码肯定是要重构的,所以现在还不支持。
这里不讲解内核驱动程序opendla.ko是如何编译的,如何编译看这篇文章。这里要注意如果直接拿NVDLA官方的仓库里的umd来编译在tengine里是无法work的,有一些编译链接的问题,以及自己custom了一些代码,比如解决了量化的一个BUG和增加了INT8的分组卷积的实现。
2.4.0 载入内核驱动程序
1 | |
使用dmesg查看内核日志:
1 | |
查看是否注册了nvdla的中断以及nvdla驱动所需的设备renderD128是否存在来确定是否真的安装完成驱动了:
1 | |
2.2.1 编译libjpeg6b
如果是aarch64,跳过该步骤即可,直接使用仓库里的libjpeg.a.
1 | |
2.2.2 编译libprotobuf.a
1 | |
2.2.3 编译 Compiler 与 Runtime
1 | |
这样在out目录下就会生成所需的lib,将lib和include拷贝到Tengine目录下:
1 | |
2.2.4 编译 Tengine
1 | |
2.4 RESNET18-CIFAR10 推理演示
在推理之前,需要做模型的转换和量化,这两个工具分别在源代码的tools目录下,使用方法详见:
RESNET18-CIFAR10 需要的五个op DLA都可以支持,所以不需要做切图,完全交给DLA来运行就好,在之前的文章里使用 NVDLA 的工具链进行过评估,DLA运行的部分需要30ms,而Tengine这一套工具链运行一次只需要10ms左右,一部分原因应该是对接的Graph能吃到Tengine的图优化。
1 | |
2.5 YOLOX-Nano-Relu
YOLOX系列是旷视在今年七月提出来的目标检测网络,这里要特别感谢旷视的大佬们为了迁就DLA Finetune的Yolox-Nano-Relu版本!
而要在Tengine上运行Yolox不止需要做模型的转化、还需要把前处理的Focus去掉,详见虫叔之前写过的文章。
注:可前往 Tengine 的 Model Zoo下载该模型。
1 | |
这里的683是整个Focus的输出Tensor,即第一个Conv节点的输入Tensor,output是整个网络的输出Tensor。
量化:
1 | |
在这里,大家不要对推理速度报太多的期望。在FPGA运行的加速器多是为了验证,FPGA本身的性能不太行,Small配置下的NVDLA只能跑到100Mhz、中国科学院信息工程技术研究所流片过一块Small、可以跑到800Mhz(不知道当时用的是几纳米的工艺),而本设计用的也是最小的8乘8的MAC阵列,可以增加到32乘32,其次也没有使用GlobalSram来当第二级的缓存。
1 | |

一秒一帧,嗯中规中矩的速度,主要是因为Concat被一刀切,所以切图被切成了七八块,数据来回转换浪费了时间。但是 又不是不能用!作为参考,yolov3-tiny-relu的DLA大概是600毫秒左右,Firesim的那一套用的是Large+RiscV运行Yolov3可以跑到7帧。
三、有意思的技术细节
3.1 捏一个简单的 OP Test
Tengine还有一个很方便的特性是,可以自己通过创建Tensor、Node的方式捏一个Graph,来方便我们测试一个单独的OP是否可以正常工作。
例如,捏一个只有一层relu的Graph:
1 | |
然后往里面塞数据,用create_opendla_test_graph就可以调度opendla的后端来运行程序、用create_cpu_test_graph就可以使用cpu来运行得到golden数据!
3.2 量化与反量化
原来,NVDLA的编译器完成量化首先需要借助TensorRT完成校准生成CalibTable,然后NVDLA的校准转换工具还有BUG(我给修了。CalibTable里是网络的每一个Layer对应的OutputScale、而其权重是通过编译器统计minmax完成的量化。
Tengine的量化工具原理与TensorRT一致,并且更好用。经过Tengine量化的模型可以直接从模型中拿到int8的weight以及int32的bias数据以及量化的时候得到的量化参数,然而NVDLA原来的编译器虽然写了部分INT8的支持代码,但估计是因为他前端只能吃Caffe的模型没办法验证直接拿INT8的代码塞到AST上能不能work,所以我试了半天有一堆BUG;更奇葩的是,他支持FP32、FP16、INT16、INT8,但是唯独没有INT32这个类型。
由于之后考虑到要重构IR,不准备在原来的Compiler上增加INT8和INT32的支持,所以这里参考Tengine的TensorRT后端进行了反量化,然后再由编译器进行minmax的量化。
1 | |
所以现在的流程是,INT8->FP32->INT8,会带来微乎其微的失真,比如个别weight会差个1,但是不影响精度,在重构IR的时候会得到解决。
3.3 Average Pooling 的量化透传问题
起初调试Resnet18-CIFAR10这个模型的时候精度总是失真严重。在漫长,漫长的debug中发现,当把Global Pooling切到CPU上运行的时候精度就会恢复正常!于是我对比了CPU的AVGPooling与DLA的AVGPooling的输入和输出终于发现了问题。DLA的Pooling运算不知道是为了偷懒还是啥,没有给Pooling逻辑设计Scale单元,这就要求AVGPooling的输入和输出Scale需要保持一致。
这个时候我想,为什么TensorRT量化出来的就可以work呢?!结果发现TensorRT量化完成的 GlobalAVGPooling 的输入Scale和输出Scale就是一样的,根据Tengine 的量化专家说,这个机制是avgpooling的量化透传,而Tengine的量化工具目前还没有实现这个。
那么,如何解决这个问题?
就在我准备试着改Tengine的量化工具的时候,Tengine的量化专家@走走经过一通理论分析,“你可以先试试把Scale从前往后传,或者从后往前传试试”,于是有了下面这段代码:
1 | |
结果,他真的可以work!而且经过一些简单的测试发现从前往后传要比从后往前传看起来效果好一些,给理论大师献上我的膝盖。
3.4 DLA的数据摆放
NVDLA的数据摆放,或者说加速器基本上都需要特殊的数据摆放格式,以方便运算单元访存,遗憾的是NVDLA没有提供数据摆放的电路这导致整个工作需要使用CPU来完成。NVDLA的数据摆放在in memory data format这一小节,但是官方举的例子是以32*32的PE阵列来计算的,本设计使用的是8*8,讲的也不是很清楚。这里我们只讲述FreatureMap是如何在内存中摆放的。
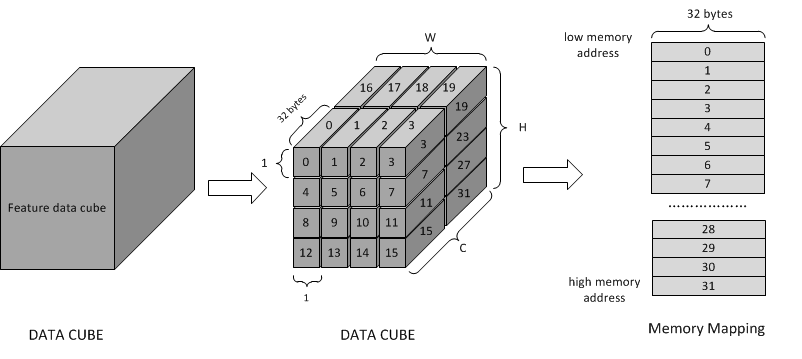
NVDLA将 Featuremap 以一个PE的大小来做切分,例如官方给的例子里,PE的长宽都是32,那么按照如下优先级来切:
In conclusion, mapping in memory follows pitch linear format. The order is C’ (32byte) -> W -> H -> C (surfaces). Here C’ changes fastest and C changes slowest.
其实,简单来讲就是,第一个通道的第一个数据摆在内存的第一个位置、第二个通道的第一个数据摆在内存的第二个数据,内存的前32位摆放的是前三十二个通道的第一个数据,内存的31~63位摆放的前三十二个通道的第二个数据。然后依次类存,数据是从以c->w->h这个优先级来展开。
总结一下,那么数据摆放的代码就可以按照如下的逻辑来实现。
1 | |
前面提到了这部分工作需要使用CPU来完成,如果整个网络都在加速器上运行那么只需要拷贝一次输入的图像与一次输出的数据就可以了,计算量微乎其微。然而,如果考虑到要切很多图的情况,那么中间的Featuremap的数据量轻轻松松就可以达到百万字节的数量级,无疑是很耗费时间的。因为由于其不规则的摆放格式导致没有办法像使用memcpy这样的块拷贝,只能单个字节单个字节的拷贝,不过考虑到其中存在很高的并行度,于是代码里写了SIMD,利用OPENMP完成了多核展开进行了简单的并行加速处理。
但是这部分工作交给CPU来做还是有些不合适的,根据Tengine的架构师@极限的讲述,针对加速器的时候数据摆放问题还是很常见的,但是很多都有硬件支持,比如芯原底层,有个 tensor process 单元非常快的做这个事,比如 nvidia tensor core。
这一小节还要感谢一下浙江大学的周帅同学,在一年前我们都选做NVDLA来做自己的毕业设计认识。周帅是基于Chipyard用rvv+dla写寄存器之类的工作,并通过配置寄存器的方式完成了lenet5的推理,而这也使得他对内存摆放的研究比较深入,DLA的内存摆放问题多是有向他请教。
3.5 Fake INT8 Group Conv
虫叔拜托了旷视的大佬帮忙迁就了一下DLA训练了一个都是Relu激活函数的 Yolox-Nano、结果我高高兴兴拿到模型调试了半天发现原来是不支持 Group Conv、但是又不好意思再麻烦训练一个 Yolox-Tiny,于是一通分析之后将 Group Conv 换成了直接 Conv,以网络中出现的第一个 Group Conv 为例:
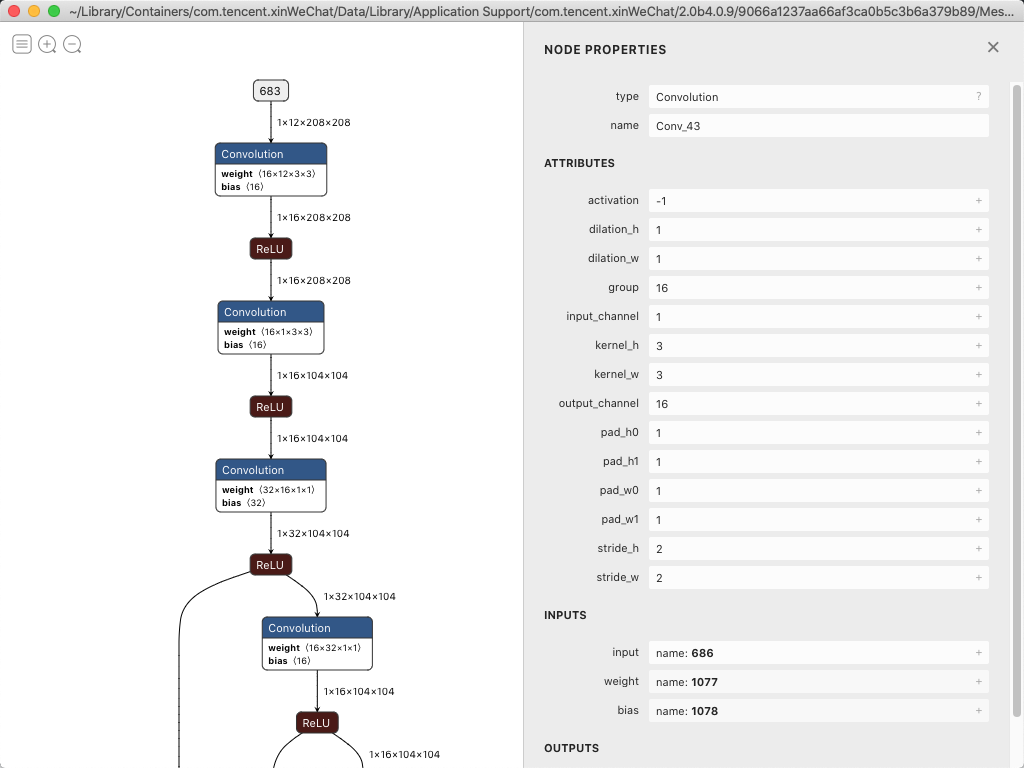
原来,网络的输出特征图应该是这样计算:
$$
Output_0 = Input_0 \ast filter_{0_0} + Input_1 \ast filter_{0_1} + … + Input_15 \ast filter_{015}
$$
输入的Channel是16、Group也是16,那么输出的特征图这样计算:
$$
Output_0 = Input_0 \ast filter{0_0}
$$
可以看到,如果两者需要等效,则需要把fitler_0除了第0位全都清零,需要把filter_1除了第一位全都清0,则那么,手动把weight_tensor扩展为输入为十六个通道,Group设为1,然后在对应的位置上把值塞进去,这里可以看dump下来的INT8的数据,一个虚伪的分组卷积就完成了(虽然增大了计算量:
1 | |
3.6 一些方便调试的宏
export TG_ODLA_DEBUG_DATA=1会在当前目录下生成每个subgraph的loadable,以及每个subgraph的输入输出数据、每一层的Layer量化之后的数据是多少。
export TG_DEBUG_TIME=1会输出CPU跑了哪些算子,耗时怎么样。
export TG_DEBUG_DATA=1会在当前目录下生成CPU跑的每个Node的输入和输出。
3.7 接下来需要做的事
3.7.1 全新的IR
现在用的IR还是用的NVDLA的编译器里的,其设计很难做一些额外的工作。这部分的工作也有参考,前面提到的ONNC就有一套自己的IR这是可以借鉴的,相比NVDLA原来的AST,需要增加能够直接载入INT8权重的能力、能够支持算子拼接的能力可以支持更多算子等。
3.7.2 模拟器开发
NVDLA的官方是有提供CMOD模型的,他原本的作用是挂载到QEMU上做仿真、得到Golden数据。Tengine后端支持的TIM-VX提供了这样一个模拟器的接口,也就是仿真环境。一般模拟器开发也是先于硬件开发,用高层语言把功能实现,更快地做一些评估,有了这个模拟器也是很方便的,相比之下连着板子开发还是有一些不便。
3.7.3 硬件也可以重构
为什么官方生成RTL需要搭建一个tmake,需要那么多工具作为支持?为什么判断使能某些模块、PE阵列大小的时候要用C语言的宏作处理而不是Verilog自带的宏定义来做?我认为这些代码应该可以都是用verilog来做,只不过重构是个体力活。
硬件这边也有许多可以做得地方,比如把原来的PE阵列运用上Eyeriss的dataflow,比如之前提到的加上一个硬件实现的摆放数据的单元。其次,硬件没有实现Concat运算,NVDLA的做法是让Concat之后的算子改变访问Concat之前的数据的位置,在内存中数据并没有真正做拼接,看起来还是比较智慧的。但是这导致Concat必须夹在DLA能够支持的算子中间才可以正常工作,而yolo系列的网络里,总会有一两个Concat不符合这个情况而在切图的时候被一刀切,把所有的Concat都调度到CPU上运行。然后,其核心的MAC阵列在Xilinx FPGA上被映射到查找表实现,没有使用片上的DSP,这部分加一下 Xilinx 的原语应该就可以解决,速度也会更快一些。
四、结语
其实,NVDLA的硬件已经非常复杂,想要从头到位的研究透彻这个框架涵盖的知识面很广,有体系结构领域的DSA设计workflow、Linux内核驱动的开发、应用层面的运行时和编译器也是比较硬核的知识点。而现在沉寂已久的 NVDLA 似乎有了新的起色,就我知道的有几个课题组在研究这个,大多是想把 small 流片,他们有的也苦恼于原来的工具链无法运行分类以外的网络,而笔者现在对接的 Tengine 就可以解决这个问题了,那些把 small tapeout 拿去做商业的也不需要买ONNC一年两百万的商业授权,基于 Tengine 的这一套 Toolchain 比他强的多不是吗!
大概一两年前圈圈虫大佬在ncnn社区的交流群里为刚开源的Tengine做宣传,我给点了star之后就没有关注过Tengine了。想到去年六月份我在做毕业设计想在板卡上 Debug Runtime 来排查bug,正好让我撞上了 Clion 在一两个星期前刚发布的新版本有了 Remote Makefile Debug 的支持(笔者当时使用的版本就连识别Makefile都要装插件)而NVDLA也有很多很多坑,但好在很多前人都帮忙踩过了翻翻Issue能解决大半,要感谢很多帮助过我的人呀,祝开源社区越来越好。
最后,NVDLA其实还是设计的不错的框架。就这样突然间悄无声息地停止维护没有人知道究竟是部门被砍了,还是说不想开源了?但是根据Bilibili的与Nvidia合作过这个项目的蔡yujie同学的描述,似乎是真的没人搞了。但万一,突然某一天,英伟达带着内部研发了两三年的DLA与Toolchain横空出世,ONNC的价值就会消失,但Tengine却一直在那里。
Tengine的QQ交流群是 (829565581、625546458),可以来一起讨论!
Comments