近些日子在看看图神经网络这种非常稀疏的网络运算系统中有没有什么自己可以做的编译优化,其实在编译现在主流的图神经网络训练框架DGL的时候就不难注意到其依赖项里是有TVM的,这是不是说明现在的DGL也在使用TVM来进行自动调优呢?带着这个疑问我翻了一下DGL的代码,发现和tvm有关的部分只有一个叫做FeatGraph的框架,顺藤摸瓜找到了胡玉炜大佬发表在SC20上的Paper:
《FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems》
在2021年6月亚马逊云科技 Community Day 上,张建老师做的题为《图神经网络和DGL在实际落地项目中的挑战和思考》这个Talk里指出,现在主流的图神经网络框架DGL的自己裁剪的Gunrock之后制作的minigun来做运算加速的,但是根据代码大胆猜测一下实际上DGL只在在0.3~0.4中才有使用的是minigun来做一些加速,在0.5中就不使用minugun了,而是将主要的运算抽象成了SpMM(稀疏稠密的矩阵乘)和SDDMM(sampled稠密稠密矩阵乘)两种运算,这项工作在DGL达到版本0.6的时候结合tvm的高效代码生成转变为了FeatGraph发表在SC20上,而现在DGL已经前进到了0.7版本了。
FeatGraph的代码也是开源的,有效代码量只有一千多行还是很少的:https://github.com/amazon-research/FeatGraph
Motivation
最近的一段时间,有关图神经网络的论文突然暴涨,虽然现在图网络的应用还很局限,似乎还只有在一些蛋白质结构预测、推荐系统这种输入数据很呈现结构化的特点的场景中有一些比较好的应用,对于训练图神经网络的话,基于Tensorflow的图神经网络训练框架有NeuGraph、基于PyTorch的PyTorch Geometric也有很多人用,DGL支持PyTorch、Tensorflow等多个后端。但这不是我们关注的重点,图网络包含了很多稀疏和稠密的运算,稀疏是指其邻阶矩阵是非常庞大和稀疏的,对节点进行聚合需要乘这样一个邻阶矩阵,那就是一个超大的稀疏运算,论文中指出:
Empirically, sparse operations in a GNN model account for more than 60% of the total computation time, when both the sparse and dense operations are fully optimized.
最近这些年来,在稠密算子上大家已经做了很多优化了,包括tvm的高效代码生成、还有FlexTensor、Ansor这样的自动写模版、Rammer超细粒度的优化等等,感觉没啥油水可以榨了呢..但是在稀疏算子上的运算做的优化工作不多见。
论文里指出的已有的一些图网络工作还存在的不足:
- 一些厂商提供的算子lib,例如MKL、cuSPARSE,针对图神经网络的加速支持还不好,具体表现为只支持图网络用到的一小部分算子的加速。
- 已有的一些针对图的算法,BFS、PageRank的节点都是和标量绑定的,但是图网络处理的问题节点与tensor绑定。
- 之前的一些工作,可能关心了在图网络中通过图分割的方式提高cache利用率的问题,但是没有考虑到feature这个维度,featGraph文章里做了graph partition和feature tiling两种调度。
DGL等框架来做编程模型和自动微分,FeatGraph主要是作为这些框架的一个后端来cover message passing 计算的速度。
主要工作
- 啥是SpMM和SDDMM?

对于GCN来说,图神经网络针对节点的聚合运算就是把与其相邻节点的信息直接求和,那么他就可以表示成邻阶矩阵A乘特征矩阵X_ V,邻阶矩阵是非常稀疏的,特征矩阵相对来讲稠密一些,这样的运算被定义为SpMM(sparse-dense matrix multiplication) ,那么其集合的结果其实就是。对于边的聚合流行的算法是将边的目标节点和源结点的feature进行点乘,这样就是4式,该运算被定义为SDDMM(sampled dense-dense matrix multiplication),由两个稠密矩阵乘与一个稀疏矩阵乘组成。
通过构建一个两层的GNN网络,使用现有的加速方案SpMM和SDDMM的计算时间会占据总运算时间的95%左右,而面对日益丰富的聚合算法,GunRock显得不够灵活,不能充分的发掘这些新算法的并行性,FeatGraph的解决方法是借助现有的AI编译器TVM,使用tvm来构建了SpMM和SDDMM两个kernel运算,并且可以比较方便的实现很多message function。
- graph partition
假设我们有下面这张图:
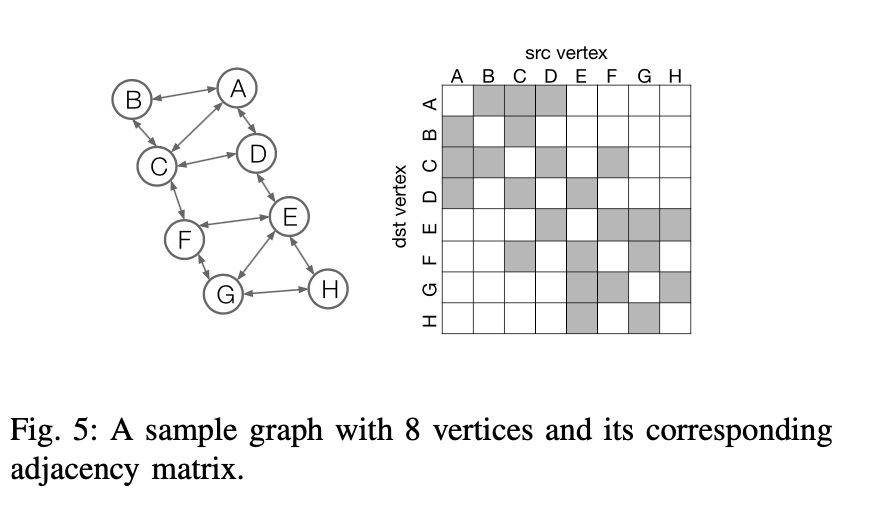
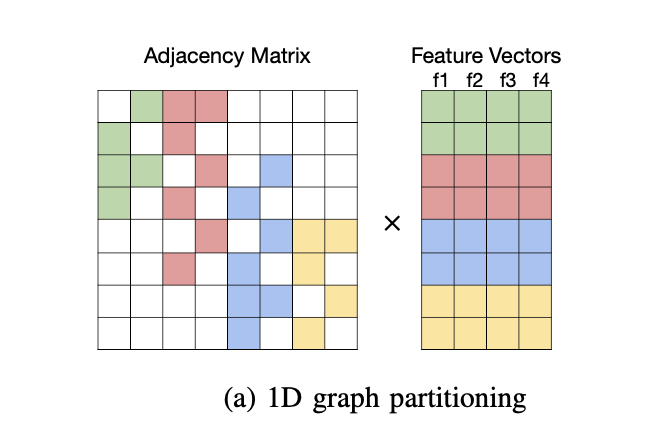
他的邻阶矩阵是左边的图,假设feature的长度是4,运算的cache里能放两个feature,那么原来8个节点的feature最好被拆成4份分别进行运算,算完之后再把中间结果取出来,从而减少cache miss rate.
- feature dimension tiling
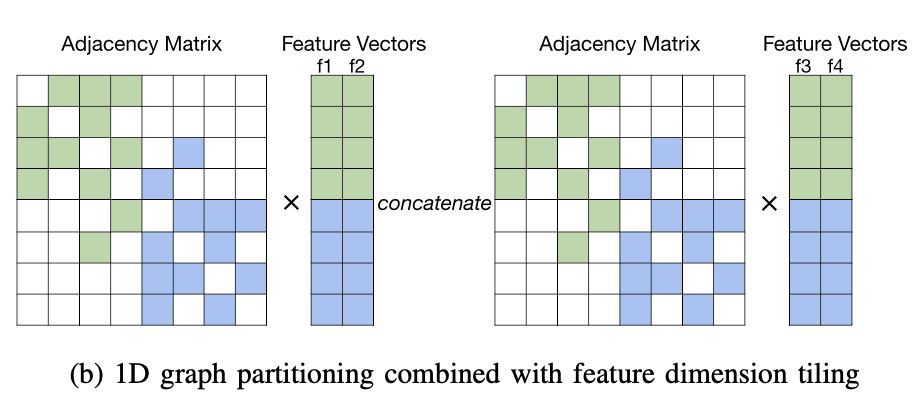
feature dimension tiling是指,将原来的feature从一个长度为4的,拆分为两个长度为2的,这样cache里一次就可以存放4个结点的feature,减少了merge的开销,但是这样又会导致遍历两次邻阶矩阵。所以feature dimension tilling是一个对邻阶矩阵和特征矩阵访问的trade-off。
- UDFs和FDS

FDS是对dimensions级别的调度,具体就体现在上面的函数。
UDFs指的是可以自定义message passing function(个人理解哈.

结果
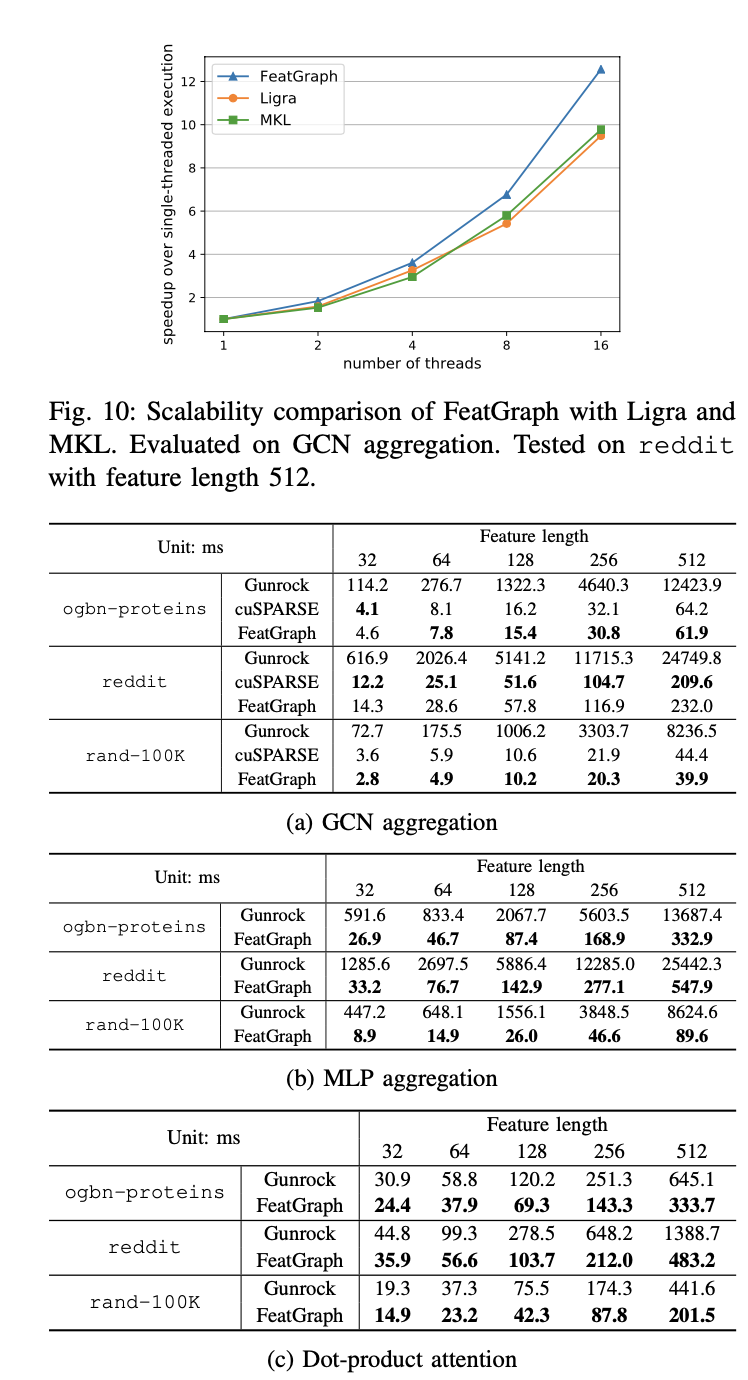
Performance如图,看起来还是很不错的,但是看完了这篇文章我比较迷惑,这不还是加速稠密矩阵运算那一套思路么?关于软件加速稀疏运算是有什么奇技淫巧吗,还是说必须得靠硬件单元做支持才能做不失真的加速运算?
Comments