最近给BitBLAS添加了AMD的后端,发现AMD的异步拷贝等和Nvidia有很大的不同(但是FA3在MI300上需要用到这一个Feature),然而官方根本没有文档,只有Instruction Set,我在这里做一下自己的理解和解读,大部分内容是参考自这个Instruction Set。
异步拷贝
首先回顾一下 Nvidia 架构上的异步拷贝:
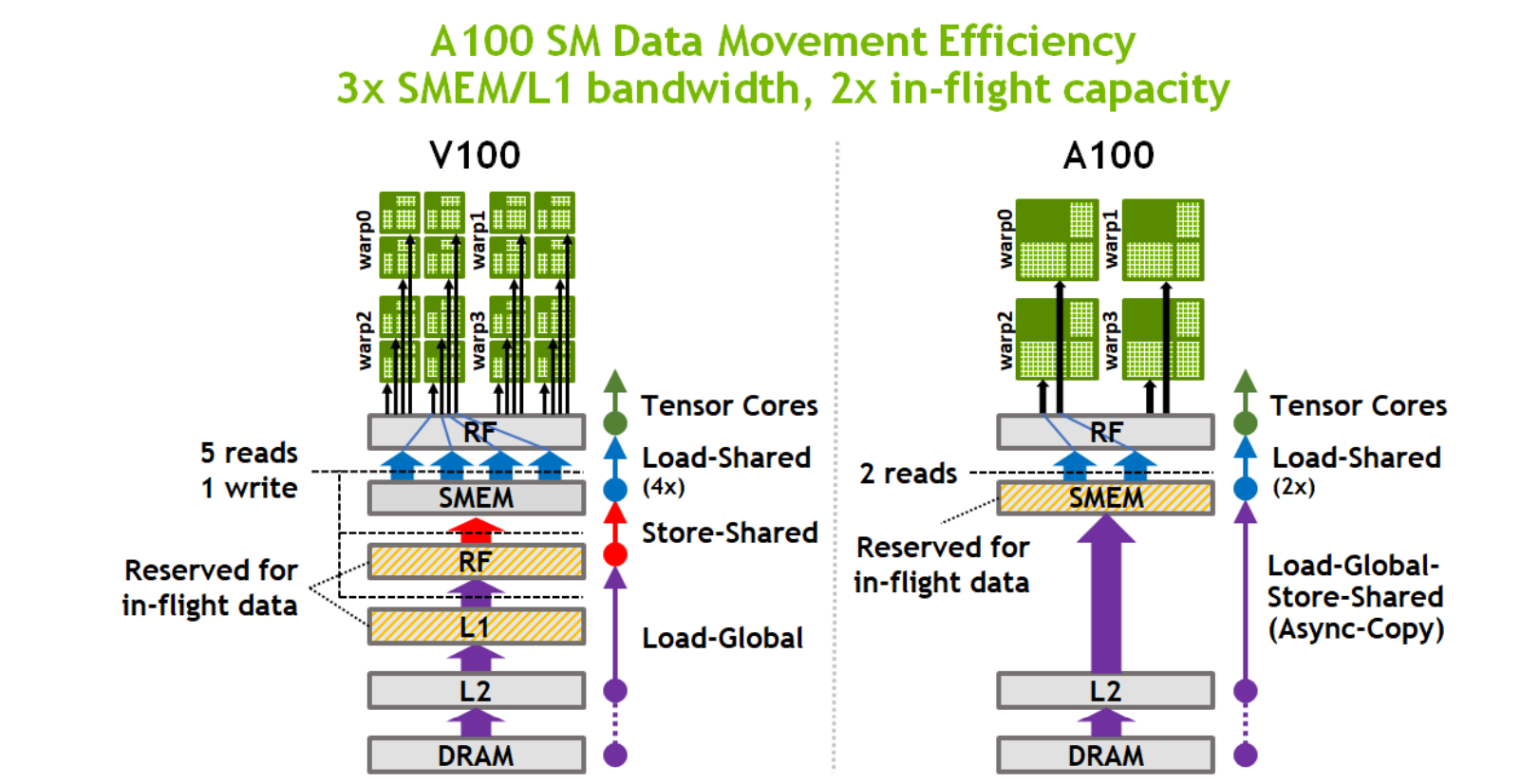
这个指令的引入可以分别做到计算Core和Load/Store的Pipeline,并且可以节省寄存器文件的开销,缓解Kernel对寄存器文件的压力。
和Nvidia不同,AMD的异步拷贝可以被看做是Nvidia的异步拷贝拆开的两个部分:
- 异步的 load gmem to register/ register to shared 的过程,然后使用同步原语来sync。
- 直接的 global memory to shared memory的通路
注意: 在AMD的架构中,Global Memory一般被缩写成GDS(Global Data Share,全局数据共享),而Shared Memory被缩写成LDS(Local Data Share,本地数据共享)。
Async Copy的等待指令
在AMD GPU汇编编程中,lgkmcnt 和 vmcnt 是用来控制流水线的等待指令,用于优化GPU线程的同步和数据依赖,分别来看这两条指令:
指令 lgkmcnt
lgkmcnt(load-global-kernel-memory count)指令用于控制对Shared Memory和Global Memory的数据加载操作的等待计数。
注意,此处用大家都比较熟悉的Shared Memory,跟前文中提到的一样实际上AMD的Local Memory和CUDA的Shared Memory是一个东西,都是指硬件上的Scratch Pad, 但是Nvidia GPU上的Local Memory是指每个线程独有的一块存在于Global Memory的存储空间,被用来虚拟溢出的寄存器文件。
具体来说,lgkmcnt 指令用于等待内存读取操作完成,这些内存操作包括:
- 从Shared Memory读取数据。
- 从Global Memory(显存)读取数据。
当一个线程发起多个读取指令时,GPU可能会因为内存操作未完成而阻塞接下来的计算操作,通过设置 lgkmcnt,可以指定“最多等待多少个 lgkm 相关操作完成”,从而避免线程因为等待内存操作而过度阻塞,完成异步拷贝。
1 | |
表示等待所有的 lgkm 相关操作完成,再继续执行后续指令。lgkmcnt(1) 则表示最多允许等待 1 次 lgkm 操作的结果完成,等等。
这个和nvidia ampere架构引入的cp.async.wait_group相似(此处的N代表可以等待1个,也就是说允许一个异步拷贝的commit在DMA上完成拷贝的同时接着执行下面的指令):
1 | |
指令 vmcnt
vmcnt(vector memory count)指令用于控制对矢量内存(Vector Memory,其实就是Global Memory,不知道为啥整这么多名字)的数据加载操作的等待计数,它和 lgkmcnt 类似,但 vmcnt 仅控制显存操作的等待,而不控制Shared Memory的操作。
例如:
1 | |
表示等待所有显存加载操作完成后,才继续执行后续指令。vmcnt(1) 表示最多等待 1 次显存加载操作,等等。
和Nvidia的对比发现,他没有commit的概念,应该是默认一条load gmem/smem的指令自动commit。
ByPass Resgiter Files
但是不难发现,这和Nvidia的异步拷贝还是有一定的区别的,因为Nvidia的异步拷贝有一个很重要的功能,就是ByPass Register File,直接将数据从Global Memory拷贝到Shared Memory,而不是先拷贝到寄存器文件,然后再拷贝到Shared Memory, 这样可以节省大量的寄存器文件,在计算卡(A100, H100等)这一特征非常重要。
上述的AMD的异步拷贝虽然在一定程度上可以做到异步,但是不能做到ByPass Register Files,而且这一个异步拷贝的Feature在十年前就已经存在了(但是基本没啥人用)。
在MI300上,ByPass Register Files的指令终于有了,如果一个global load的指令后面带lds的话,就代表这个指令会把数据直接拷贝到Shared Memory, 例如:
1 | |
但是,有意思的来了,翻遍指令集,只有这一个指令是带lds的, 但是这个指令只能load一个double word, 也就是4个字节,但是理想的transaction长度应该是16个字节,这样才能保证最大的带宽利用率,这不免让人感到confused,我幸运的在GPU Mode社区碰到了Composable kernel的作者,结果也和我猜想的一样:
用这一个bypass寄存器文件的指令对带宽利用来说其实是不友好的,但是好处是可以节省寄存器,在一些寄存器开销特别大的应用中,这个指令就显得很重要了,因为可以缓解寄存器压力(不然就会造成register spill, 直接用global memory当做寄存器文件),否则性能会很差,其实看Composable Kernel的源代码,不难发现只有Flash Attention使用到了这一个Feature。
然而,这个指令也还是很难用,CK里这个指令需要和其他的一系列指令组合使用,包括之前提到的lgkmcnt和vmcnt,还有一个特殊的M0寄存器。

代码中会涉及到类似init_m0和inc_m0的操作:
1 | |
M0 寄存器是一个特殊的寄存器,主要用于管理内存访问的地址偏移或控制数据的传递,它可以用来设置每个线程对共享内存的不同偏移量,从而实现对共享数据的灵活访问(有一点ldmatrix这个指令的味道在里面,但是不多)。
总结
综上所述,AMD的异步拷贝严格意义上不是MI300才引入的,而是一个存在了很久但是没人用的Feature,MI300上引入是一个从Global Memory直接到Shared Memory的DMA,而且相比原先的通路来说反而利用好带宽变得更加困难,其主要的功能是节省寄存器文件的开销(最典型的寄存器文件怪兽 Kernel 就是Flash Attention),也可能是为了Flash才设计了这样一个功能?这不得而知。
最后,不得不吐槽一句,正常人谁会去看AMD的Instruction Set呢?这对开发者来说是很不友好的,希望AMD在设计完指令之后可以提供一个像样的文档和Sample。再吐槽一句AMD社区里做BLAS的团队貌似也有独立的好几个(HIPBLAS, RocBLAS, Composable Kernel, RocWMMA, Tensile),代码风格也都不一样,目前来看RocWMMA其实比Composable Kernel更像Cutlass。
AMD还有很多有意思的问题值得讨论,例如Matrix Core(一个类似Tensor Core的计算单元)的Layout,如何做Swizzle解决Bank Conflict, 在OSDI 24’ Ladder这篇论文里,作者(笔者)在MI250显卡上获得了比rocblas还要快许多的矩阵乘法性能,这又是如何做到的呢?此处按下不表,过段时间再分享 :)
Comments