这两天在京举办的第六届 ChinaDA 的学术研讨会是我第一次参加的学术会议,写下本文记述一下会议上比较感兴趣的点。篇幅不会长,主要是因为会前没有挑几个自己感兴趣的报告专门认真听一下,也没有没有做笔记、拍视频照片。

PS:这张大会的Banner页是我做的!
ChinaDA是国内集成电路设计、自动化没计(EDA)等学科青年学者自发组织的学术共同体,其使命是推动国内集成电路设计、EDA,及与之交叉的计算机体系结构和工艺器件等领城研究,为青年人搭建同行学术交流平台,提高本学科在国内科研界的地位。ChinaDA自2018年特殊时刻创建以来,每年举办2次,本次是第6届。
这次有三篇大佬的 Keynote Speech:
- 朱晓波,中国科学技术大学:下一代超导量子计算与EDA软件系统
- 张悠慧,清华大学:从计算机系统角度看类脑计算研究
- David Z. Pab,The University of Texas at Austin:Toward Agile and Open Electronic Design Automation
说来惭愧,第一篇关于超导量子计算应该是本次大会里我听得最认真的演讲,可能是因为量子计算听起来与参会各位的研究方向比较遥远,所以朱晓波老师讲的很亲民。
首先,超导量子指的是引入了约瑟夫结(由两个通过绝缘体连接的超导体组成的)的量子电路。约瑟夫结可以类比到PN结,但是由于量子隧穿效应,可以维持超电流而无需任何电压。听到这里我不禁想,听起来没有功耗?朱晓波老师指出超导量子比特控制量子态的能量大约只相当于一个蝴蝶扇动翅膀能量的十亿亿分之一,这个功耗是十分低的,但热量会产生噪声干扰量子比特从而影响性能,于是虽然量子本身的功耗微乎其微,主要的开销花在外围的冷却设备上。更进一步地讲
目前的量子计算系统运行的一个重要限制因素是:虽然它们的超导量子比特可以在低于1K的低温中正常工作,但所有负责控制和读出的电路却必须在室温条件下才能运行。对于目前的低于100-qubit的系统,专用射频电缆进出的空间是足够的,但是要扩展到百万级比特运行的系统中去处理更复杂的问题,那就没有足够的空间。
朱晓波老师有提到在低温IC的设计上,国内是落后于国外很多,其次是团队设计的IC虽然有上万根连线需要绘制,但是缺乏相应的的EDA工具支持,只能以手动布线加写脚本的方式完成。
然后我还记得有提到什么量子优越性、保真度等等概念啦,其实我也不知道是啥意思。最后,朱晓波老师让各位参会的同仁们理性看待媒体的报道:D,凡是强调自己做的量子比特数目多的那么性能就不好,凡是强调性能好的那么量子比特的数目一定不多。朱晓波老师在保证性能的前提下做到了现在的世界第一(最新版本的祖冲之号,66个量子比特,110个耦合器,数万个空桥结构),让原来就觉得很厉害的工作变得更厉害了!
张悠慧老师的演讲,我只能依稀记得老师在讲一些理论框架的定义了、比如类脑计算完备性、图灵机来图灵机去的,以及定义了自上而下的系统层次结构等,有一些枯燥的理论还有很牛的证明,但是我听不懂!而且发现了张老师口头禅,“对吧”(大概是。
David Z. Pab 老师的演讲我其实很期待,因为他的自我介绍都是英文,想着是不是英文的talk,听一听现场版是啥样的,但是因为太困了睡过了就没听到。
其他主要的环节就是几个 Session,分别是:
DAC论文预讲之EDA与机器学习
Synchronize-Free Sparse LU Factorization for Fast Circuit Simulation on GPUs
这篇报告专业名词太多了,没有听懂:( 但是了解到有这个方向,使用GPU加速电路仿真的工作。
SPICE 是当今最常用的电路仿真器,但是针对现在的超大规模集成电路的快速发展,后仿真的寄生参数提取后的电路矩阵的尺寸很大,使得在CPU上进行后仿真需要几天甚至数周才能完成,其最耗时的两个步骤就是利用LU分解求得稀疏矩阵方程和参数更新。这两个步骤要被迭代许多次,已经成了SPICE仿真器的瓶颈,有一些的工作围绕该方向展开,比如针对CPU进行稀疏矩阵算法进行优化,利用GPU挖掘计算的并行性等。
迈向通用存算一体架构–如何提供灵活性(完全不记得有在讲啥了)
A Provably Good and Practically Efficient Algorithm for Common Path Pessimism Removal in Static Timing Analysis
Common path pessimism removal(CPPR)在 2014 年被提出,工艺-电压-温度的变化被称为片上变化(OCV),而悲观考虑(OCV derate)是指在静态时序分析期间,都会为了保证设计来为这些参数保留一定的余量。但是这些余量会增加时序收敛的难度,而CPPR是一种从时钟路径中安全消除过度悲观的方法。
这片DAC论文是说打开了CPPR会极大的延长时序分析的运行时间(10倍~100倍),于是对CPPR的算法进行了改进,加速了分析时间。
Bayesian Inference Based Robust Computing on Memristor Crossbar
忆阻器神经网络、贝叶斯推断,但我完全忘了在干嘛了。
开源EDA与电路设计
超大规模电网络方程的快速迭代解法
清华貌似有很多做电网方向的,本科推免到清华的好朋友也在从事这方面的研究。
模拟电路的自动拓扑优化
VLSI Mask Optimization:From Shallow To Deep Learning
一个基于机器学习算法设计异构框架帮助掩模布局优化的工作,可以缩短VLSI设计的周期。
混合粒度可重构阵列的敏捷生成工具
开源EDA探索与实践
解老师分析、总结了一些著名的开源EDA软件有点和缺点。
AIoT芯片与系统
AIoT的含义是 AI + IoT,是AI与物联网在实际应用中的融合,也是近几年的热点了,在今年的RVV的峰会上也有不少相应的产品。
模拟“感算共融”计算范式和持续智能感知集成电路系统
面向高级别自动驾驶的失效可操作电子电气信息架构
智能物联网AIoT芯片的挑战与发展
A 2.75-to-75.9TOPS/W Computing-in-Memory NN Processor Supporting Set-Associate Block-Wise Zero Skipping and Ping-Pong CIM with Simultaneous Computation and Weight Updating
专用处理器
A 5.99-to-691.1TOPS/W Tensor-Train In-Memory-Computing Processor Unsing Bit-Level-Sparsity-Based Optimization and Variable-Precision Quantization
DADU-机器人专用处理器

NN-Baton: DNN Workload Orchestration and Chiplet Granularity Exploration for Multichip Accelerators

软件定义加速器–KPU
KPU 架构是基于中科驭数首创的软件定义加速器技术路线而研发的领域专用计算芯片架构。相较于传统的ASIC或SOC DPU芯片架构,具有极高的灵活性,可以通过即时的软件配置来定义芯片内部数据运算逻辑,在保障充沛算力的同时,以最低功耗支撑更多运算负载类型。
架构图:
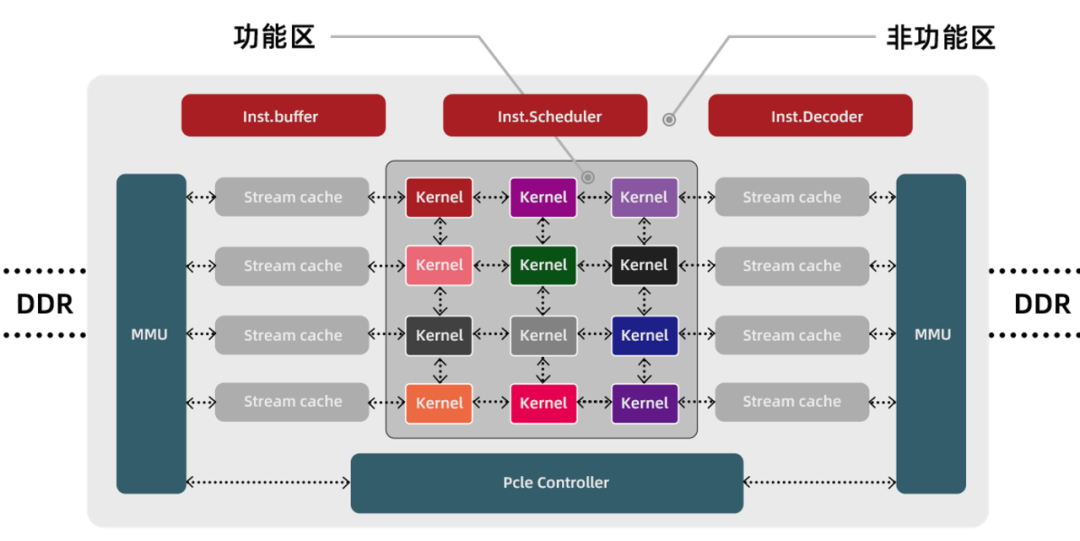
卢博士讲的还是比较抽象的,很像来拉赞助的讲法,不知道架构图里的 Kernel 是啥什么结构,不会是一个一个的 GPU 吧。
新型存储与应用
当下存算一体进一步提升能效困难,且收益不高,密度、准确度更关健;然后,工艺偏差带来的计算骗差对不同网络精度的影响需要讨论;再者,数据加载瓶颈急需解决;还有量化算法的截取范围问题;合适的SRAM阵列大小和个数也是需要思考的问题;最后就是端到端的算法编译部署。
WTM2101存算一体SoC的应用
新一代闪存存储系统服务质量优化技术研究
SRAM存算一体芯片
Enabling new intelligent computing paradigms with capacitive multi-level content-addressable memories
DAC论文预讲之新型计算系统
这部分的工作很多都是围绕着RRAM开展的,而RRAM,指的是Resistive Random Access Memory,这是最近才新研究的技术,并不成熟。利用Memositor(一种记忆电阻,其阻值会根据流过的电流而变化)作为存储单元,优点十分明显,并且和DRAM比起来在array中可以减少控制晶体管的数量,在CMOS chip上已经有所应用。
基于RRAM的模拟计算:神经网络加速和线性方程组求解(陈晓明大佬的工作,很高端
Reinforcement Learning-Assisted Cache Cleaning to Mitigate Long-Tail Latency in DM-SMR
ASBP: Automatic Structured Bit-Pruning for RRAM-based NN Accelerator
Accelerating 3D Convolutional Neural Networks in Frequency Space
新型架构设计技术
ABC-DIMM: Alleviating the Bottleneck of Communication in DIMM-Based Near-Memory Processing with Inter-DIMM
TENET:A Framework for Modeling Tensor Dataflow Based on Relation-Centric Notation
3M-AI: A Multi-Task and Multi-Core Virtualization Framework
PipeZK: Accelerating Zero-Knowledge Proof with a Pipelined Architecture
最后一篇 Talk,是北京大学毕业的,也大不了我几岁的张烨博士的演讲,一半中文一半英文的演讲听的我有点不适应,总的来说应该是在可信计算加速做的工作。两机通信的时候,某算法会要求从机做数据校验,但是当文件数量比较大的时候、或者说保证可信度高,那么校验的时间就会长,但是算法又要求需要控制在很短的时间内完成该工作,所以有需要设计这个加速器,这个motivation很明了。
会议总结:
参会的不只有学术界的同仁,一些工程师也会过来。学术会议的另一个收获大概就是跟大佬们一起吃午饭交朋友,与我们坐在一起吃午餐的是华为2012实验室的工程师,他们在项目遇到瓶颈的时候会来看看学术界最近的研究方向,找一些灵感。了解到华为的实验室的实力真的强悍,只要这个方向有价值就可以砸钱砸人,人多再加上一个可行的idea什么事都能做成。华为内部也探索过很多的加速器设计,总结经验就是最后都是访存成为了瓶颈,这次会议上就有很多存算一体的设计进展,但是不如近存计算来的靠谱。
Comments