翻译自: https://tilelang.tile-ai.cn/tutorials/debug_tools_for_tilelang.html
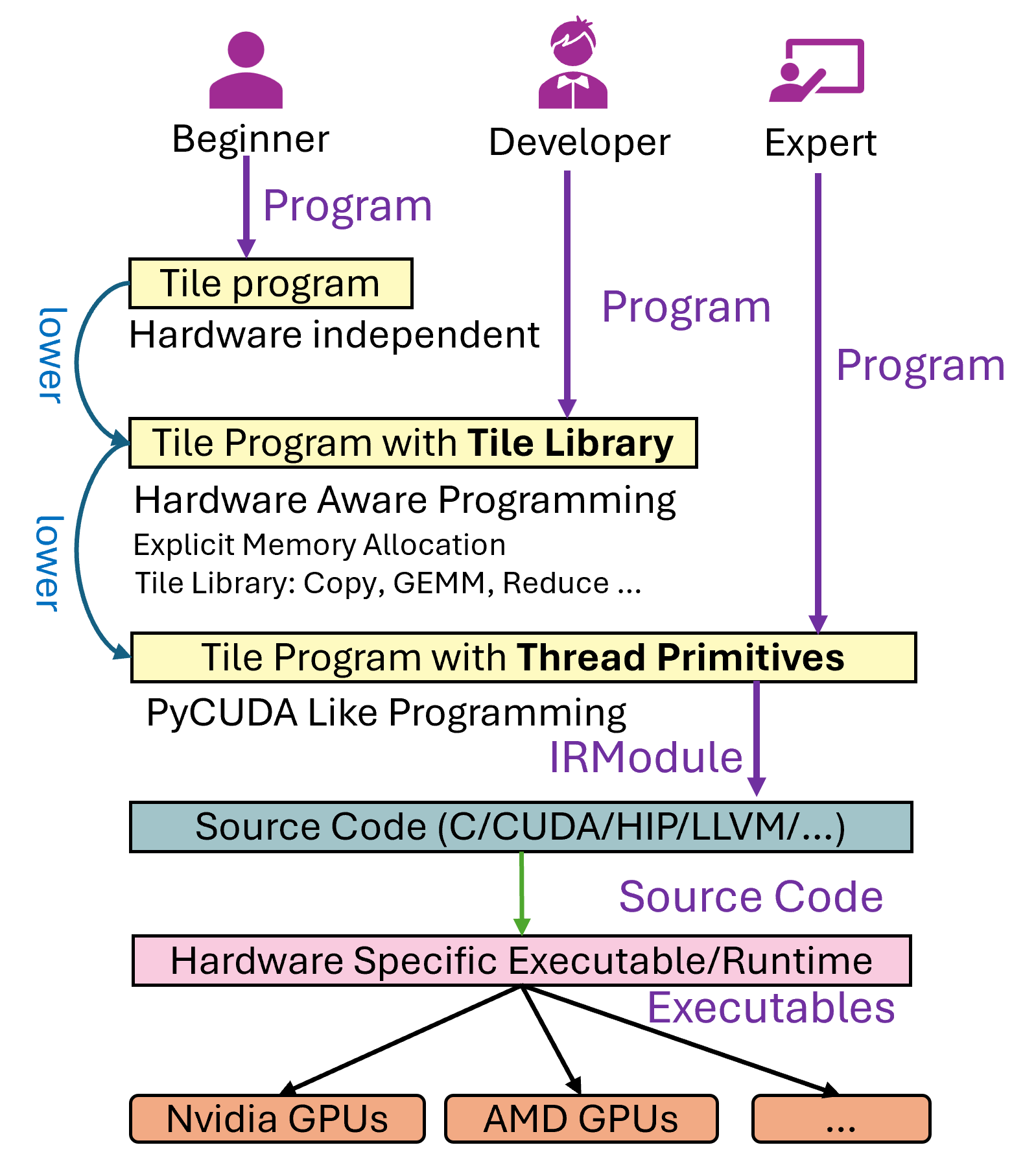
一个Tile Language程序(我们称为 program)到具体的硬件可执行文件的流程如下图所示,大致分为以下几步:1. 用户首先编写 Tile Language program。2. 程序会经过多个 Pass 的转换和优化处理(即 lower 阶段,相关代码位于 tilelang/engine/lower.py),最终生成中间代码,比如针对 CPU 的 LLVM 或 C 代码,或者针对 NVIDIA GPU 的 CUDA 代码等。3. 生成的中间代码会通过对应的编译器进一步编译,最终输出硬件可执行文件。
在这个过程中,用户可能会碰到大概三类问题:
1. Tile Language Program无法生成硬件可执行文件,也就是lower的过程中出现问题,我们可以归纳成生成问题。
1. 正确性问题,生成的可执行文件运行后,行为不符合预期。
1. 性能问题,执行文件的性能表现与硬件的理论值存在显著差距。本文将重点讨论前两类问题的调试方法。至于性能问题的调优,则需要结合硬件厂商提供的性能分析工具(如 Nsight Compute 、rocProf 等),通过分析具体的硬件指标进一步优化,我们将在后续文章中详细探讨。
接下来,我们以矩阵乘法(Matrix Multiplication)为例,使用 Tile Language 展示如何编写和调试相关程序。
在 Tile Language 中,可以使用 Tile Library 提供的接口实现矩阵乘法。以下是一个实现矩阵乘法的完整程序示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import tilelangimport tilelang.language as Tdef matmul (M, N, K, block_M, block_N, block_K, dtype="float16" , accum_dtype="float" ): @T.prim_func def main ( A: T.Buffer((M, K ), dtype ), B: T.Buffer((K, N ), dtype ), C: T.Buffer((M, N ), dtype ), ):with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), threads=128 ) as (bx, by):for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3 ):for k, j in T.Parallel(block_K, block_N):return main1024 , 1024 , 1024 , 128 , 128 , 32 )2 ], target="cuda" )import torch1024 , 1024 , device="cuda" , dtype=torch.float16)1024 , 1024 , device="cuda" , dtype=torch.float16)
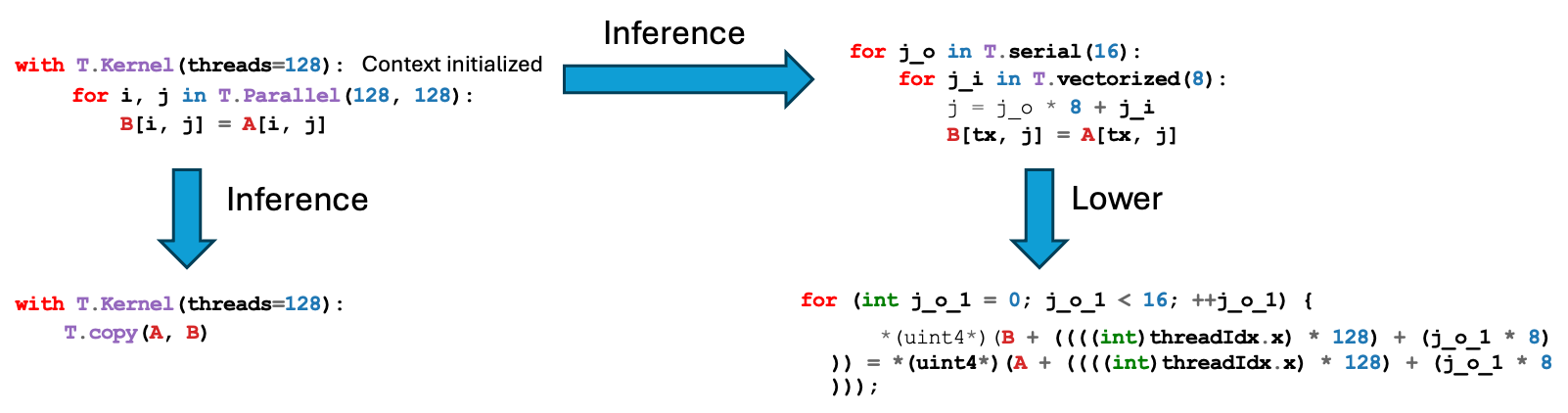
有关编译问题的排查 TileLang本质上是一个逐级lower的过程,例如T.copy首先会被展开成T.Parallel,(详见TileLang PassLowerTileOP),T.Parallel又会进一步根据上下文被展开成Thread Primitives(如T.thread_binding和T.vectorized),最终程序被lower到一个类似pycuda层面的语法树,并且被翻译到cuda c代码。
当编译问题出现,用户不必着急去检查cpp的pass代码,可以首先在python处打印抽象语法树排查。例如在社区的Issue 35(https://github.com/tile-ai/tilelang/issues/35)中,一个简单的Copy原语在dim=1的时候导致lower出现了bug,复现的代码如下 :
1 2 3 4 5 6 7 @T.prim_func def main ( Q: T.Buffer(shape_q, dtype ), with T.Kernel(T.ceildiv(seqlen_q, block_M), heads * batch, num_split, threads=128 * 2 ) as (bx, by, bz):0 , hid, :], Q_shared[0 , :])
此时tilelang的lower过程给我们的报错如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 20 : tvm::codegen::CodeGenTileLangCUDA::VisitStmt (tvm::tir::AttrStmtNode const *)19 : tvm::codegen::CodeGenC::VisitStmt (tvm::tir::AttrStmtNode const *)18 : tvm::tir::StmtFunctor<void (tvm::tir::Stmt const &)>::VisitStmt (tvm::tir::Stmt const &)17 : tvm::codegen::CodeGenTileLangCUDA::VisitStmt (tvm::tir::AttrStmtNode const *)16 : tvm::codegen::CodeGenC::VisitStmt_ (tvm::tir::AttrStmtNode const *)15 : tvm::tir::StmtFunctor<void (tvm::tir::Stmt const &)>::VisitStmt (tvm::tir::Stmt const &)14 : tvm::codegen::CodeGenTileLangCUDA::VisitStmt_ (tvm::tir::AttrStmtNode const *)13 : tvm::codegen::CodeGenC::VisitStmt_ (tvm::tir::AttrStmtNode const *)12 : tvm::tir::StmtFunctor<void (tvm::tir::Stmt const &)>::VisitStmt (tvm::tir::Stmt const &)11 : tvm::codegen::CodeGenTileLangCUDA::VisitStmt_ (tvm::tir::AttrStmtNode const *)10 : tvm::codegen::CodeGenC::VisitStmt_ (tvm::tir::AttrStmtNode const *)9 : tvm::tir::StmtFunctor<void (tvm::tir::Stmt const &)>::VisitStmt (tvm::tir::Stmt const &)8 : tvm::codegen::CodeGenTileLangCUDA::VisitStmt_ (tvm::tir::AttrStmtNode const *)7 : tvm::codegen::CodeGenC::VisitStmt_ (tvm::tir::AttrStmtNode const *)6 : tvm::tir::StmtFunctor<void (tvm::tir::Stmt const &)>::VisitStmt (tvm::tir::Stmt const &)5 : tvm::codegen::CodeGenC::VisitStmt_ (tvm::tir::IfThenElseNode const *)4 : tvm::tir::StmtFunctor<void (tvm::tir::Stmt const &)>::VisitStmt (tvm::tir::Stmt const &)3 : tvm::codegen::CodeGenC::VisitStmt_ (tvm::tir::BufferStoreNode const *)2 : tvm::codegen::CodeGenC::PrintExpr[abi:cxx11](tvm::PrimExpr const &)1 : tvm::codegen::CodeGenC::PrintExpr (tvm::PrimExpr const &, std::ostream&)0 : tvm::codegen::CodeGenTileLangCUDA::VisitExpr_ (tvm::tir::RampNode const *, std::ostream&)"/root/TileLang/src/target/codegen_cuda.cc" , line 1257 4 (8 vs. 4 ) : Ramp of more than 4 lanes is not allowed.
代码生成的时候出现了问题,而一般在代码生成阶段碰到的问题往往就不在代码生成,此时的调试方式应该是看看前面哪个Pass针对这种情况的处理是不到位的,例如此时我们在codegen pass的前面插入对ir module的打印:
1 2 3 4 5 6 7 8 9 device_mod = tir.transform.Filter(is_device_call)(mod)print (device_mod)if target.kind.name == "cuda" :"target.build.tilelang_cuda" )(device_mod, target)
可以看到此时的IR为:
1 2 3 4 5 6 7 8 9 10 11 12 13 @I.ir_module class Module : @T.prim_func def main_kernel (Q: T.handle("float16" , "global" ):16777216 ,), "float16" , data=Q)"float16" , "shared.dyn" )131072 ,), "float16" , data=Q_shared, scope="shared.dyn" )"blockIdx.x" , 32 )"blockIdx.y" , 32 )"blockIdx.z" , 4 )"threadIdx.x" , 256 )if v < 16 :64 :v * 64 + 72 :9 ] = Q_1[by * 128 + v * 8 :by * 128 + v * 8 + 8 ]
很明显这个Q_shared_1的读取范围是不对的,通过这种print方法我们就能够回溯出具体是哪个pass的处理有误,并且进行一下修复。
有关正确性问题的排查 另一种问题是,代码可以正常生成,但是结果不对,此时我们推荐用户使用两种调试方式完成程序的调试。
使用回调函数在编译前对代码进行后处理 在codegen pass执行完成之后, 程序会对生成的源代码调用一个回调函数,详见src/target/rt_mod_cuda.cc,此处注意到,当我们注册过一个tilelang_callback_cuda_postproc函数的时候,就会对生成的代码字符串进行一个后处理(此处针对amd的hip后端同理):
1 2 3 4 std::string code = cg.Finish ();if (const auto *f = Registry::Get ("tilelang_callback_cuda_postproc" )) {operator std::string ();
此时,我们在python程序中注册该函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import tilelangimport tilelang.language as Tfrom tilelang import tvm as tvm@tvm.register_func def tilelang_callback_cuda_postproc (code, _ ):print (code)return codedef matmul (M, N, K, block_M, block_N, block_K, dtype="float16" , accum_dtype="float" ): @T.prim_func def main ( A: T.Buffer((M, K ), dtype ), B: T.Buffer((K, N ), dtype ), C: T.Buffer((M, N ), dtype ), ):with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), threads=128 ) as (bx, by):for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3 ):for k, j in T.Parallel(block_K, block_N):return main1024 , 1024 , 1024 , 128 , 128 , 32 )2 ], target="cuda" )
在tilelang.lower之前注册该函数,就会在cpp这边调用后处理,在这里我们将生成的cuda代码进行打印,可以在命令行里观察到代码的中间输出结果,例如在4090上,输出内容是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <tl_templates/cuda/gemm.h> #include <tl_templates/cuda/copy.h> #include <tl_templates/cuda/reduce.h> #include <tl_templates/cuda/ldsm.h> #include <tl_templates/cuda/threadblock_swizzle.h> #include <tl_templates/cuda/debug.h> extern "C" __global__ void __launch_bounds__(128 ) main_kernel (half_t * __restrict__ A, half_t * __restrict__ B, half_t * __restrict__ C) {extern __shared__ __align__(1024 ) uchar buf_dyn_shmem[];float C_local[128 ];#pragma unroll for (int i = 0 ; i < 64 ; ++i) {2 )) = make_float2 (0.000000e+00 f, 0.000000e+00 f);#pragma unroll for (int i_1 = 0 ; i_1 < 4 ; ++i_1) {cp_async_gs <16 >(buf_dyn_shmem+((((i_1 * 2048 ) + ((((int )threadIdx.x) >> 2 ) * 64 )) + (((((((int )threadIdx.x) & 31 ) >> 4 ) + ((((int )threadIdx.x) & 3 ) >> 1 )) & 1 ) * 32 )) + (((((((int )threadIdx.x) & 15 ) >> 3 ) + (((int )threadIdx.x) & 1 )) & 1 ) * 16 )), A+((((((int )blockIdx.y) * 131072 ) + (i_1 * 32768 )) + ((((int )threadIdx.x) >> 2 ) * 1024 )) + ((((int )threadIdx.x) & 3 ) * 8 )));#pragma unroll for (int i_2 = 0 ; i_2 < 4 ; ++i_2) {cp_async_gs <16 >(buf_dyn_shmem+(((((((((((int )threadIdx.x) & 15 ) >> 3 ) * 4096 ) + (i_2 * 1024 )) + ((((int )threadIdx.x) >> 4 ) * 128 )) + ((((((int )threadIdx.x) >> 6 ) + ((((int )threadIdx.x) & 7 ) >> 2 )) & 1 ) * 64 )) + (((((((int )threadIdx.x) & 63 ) >> 5 ) + ((((int )threadIdx.x) & 3 ) >> 1 )) & 1 ) * 32 )) + (((((((int )threadIdx.x) & 31 ) >> 4 ) + (((int )threadIdx.x) & 1 )) & 1 ) * 16 )) + 24576 ), B+((((i_2 * 8192 ) + ((((int )threadIdx.x) >> 4 ) * 1024 )) + (((int )blockIdx.x) * 128 )) + ((((int )threadIdx.x) & 15 ) * 8 )));cp_async_commit ();#pragma unroll for (int i_3 = 0 ; i_3 < 4 ; ++i_3) {cp_async_gs <16 >(buf_dyn_shmem+(((((i_3 * 2048 ) + ((((int )threadIdx.x) >> 2 ) * 64 )) + (((((((int )threadIdx.x) & 31 ) >> 4 ) + ((((int )threadIdx.x) & 3 ) >> 1 )) & 1 ) * 32 )) + (((((((int )threadIdx.x) & 15 ) >> 3 ) + (((int )threadIdx.x) & 1 )) & 1 ) * 16 )) + 8192 ), A+(((((((int )blockIdx.y) * 131072 ) + (i_3 * 32768 )) + ((((int )threadIdx.x) >> 2 ) * 1024 )) + ((((int )threadIdx.x) & 3 ) * 8 )) + 32 ));#pragma unroll for (int i_4 = 0 ; i_4 < 4 ; ++i_4) {cp_async_gs <16 >(buf_dyn_shmem+(((((((((((int )threadIdx.x) & 15 ) >> 3 ) * 4096 ) + (i_4 * 1024 )) + ((((int )threadIdx.x) >> 4 ) * 128 )) + ((((((int )threadIdx.x) >> 6 ) + ((((int )threadIdx.x) & 7 ) >> 2 )) & 1 ) * 64 )) + (((((((int )threadIdx.x) & 63 ) >> 5 ) + ((((int )threadIdx.x) & 3 ) >> 1 )) & 1 ) * 32 )) + (((((((int )threadIdx.x) & 31 ) >> 4 ) + (((int )threadIdx.x) & 1 )) & 1 ) * 16 )) + 32768 ), B+(((((i_4 * 8192 ) + ((((int )threadIdx.x) >> 4 ) * 1024 )) + (((int )blockIdx.x) * 128 )) + ((((int )threadIdx.x) & 15 ) * 8 )) + 32768 ));cp_async_commit ();for (int ko = 0 ; ko < 30 ; ++ko) {#pragma unroll for (int i_5 = 0 ; i_5 < 4 ; ++i_5) {cp_async_gs <16 >(buf_dyn_shmem+(((((((ko + 2 ) % 3 ) * 8192 ) + (i_5 * 2048 )) + ((((int )threadIdx.x) >> 2 ) * 64 )) + (((((((int )threadIdx.x) & 31 ) >> 4 ) + ((((int )threadIdx.x) & 3 ) >> 1 )) & 1 ) * 32 )) + (((((((int )threadIdx.x) & 15 ) >> 3 ) + (((int )threadIdx.x) & 1 )) & 1 ) * 16 )), A+((((((((int )blockIdx.y) * 131072 ) + (i_5 * 32768 )) + ((((int )threadIdx.x) >> 2 ) * 1024 )) + (ko * 32 )) + ((((int )threadIdx.x) & 3 ) * 8 )) + 64 ));#pragma unroll for (int i_6 = 0 ; i_6 < 4 ; ++i_6) {cp_async_gs <16 >(buf_dyn_shmem+((((((((((ko + 2 ) % 3 ) * 8192 ) + (((((int )threadIdx.x) & 15 ) >> 3 ) * 4096 )) + (i_6 * 1024 )) + ((((int )threadIdx.x) >> 4 ) * 128 )) + ((((((int )threadIdx.x) >> 6 ) + ((((int )threadIdx.x) & 7 ) >> 2 )) & 1 ) * 64 )) + (((((((int )threadIdx.x) & 63 ) >> 5 ) + ((((int )threadIdx.x) & 3 ) >> 1 )) & 1 ) * 32 )) + (((((((int )threadIdx.x) & 31 ) >> 4 ) + (((int )threadIdx.x) & 1 )) & 1 ) * 16 )) + 24576 ), B+((((((ko * 32768 ) + (i_6 * 8192 )) + ((((int )threadIdx.x) >> 4 ) * 1024 )) + (((int )blockIdx.x) * 128 )) + ((((int )threadIdx.x) & 15 ) * 8 )) + 65536 ));cp_async_commit ();cp_async_wait <2 >();gemm_ss <128 , 128 , 32 , 2 , 2 , 0 , 0 >((&(((half_t *)buf_dyn_shmem)[((ko % 3 ) * 4096 )])), (&(((half_t *)buf_dyn_shmem)[(((ko % 3 ) * 4096 ) + 12288 )])), (&(C_local[0 ])));cp_async_wait <1 >();gemm_ss <128 , 128 , 32 , 2 , 2 , 0 , 0 >((&(((half_t *)buf_dyn_shmem)[0 ])), (&(((half_t *)buf_dyn_shmem)[12288 ])), (&(C_local[0 ])));cp_async_wait <0 >();gemm_ss <128 , 128 , 32 , 2 , 2 , 0 , 0 >((&(((half_t *)buf_dyn_shmem)[4096 ])), (&(((half_t *)buf_dyn_shmem)[16384 ])), (&(C_local[0 ])));#pragma unroll for (int i_7 = 0 ; i_7 < 64 ; ++i_7) {2 ));half_t )(v_.x);half_t )(v_.y);int )blockIdx.y) * 131072 ) + (((i_7 & 7 ) >> 1 ) * 32768 )) + (((((int )threadIdx.x) & 63 ) >> 5 ) * 16384 )) + ((i_7 & 1 ) * 8192 )) + (((((int )threadIdx.x) & 31 ) >> 2 ) * 1024 )) + (((int )blockIdx.x) * 128 )) + ((i_7 >> 3 ) * 16 )) + ((((int )threadIdx.x) >> 6 ) * 8 )) + ((((int )threadIdx.x) & 3 ) * 2 ))) = __1;
我们可以通过字符串操作将生成的代码进行任意的改动,例如在最前面插入一句//Hello world:
1 2 3 4 5 @tvm.register_func def tilelang_callback_cuda_postproc (code, _ ):"// hello world\n" + codeprint (code)return code
则生成的代码为:
1 2 3 4 5 6 7 8 9 10 11 #include <tl_templates/cuda/gemm.h> #include <tl_templates/cuda/copy.h> #include <tl_templates/cuda/reduce.h> #include <tl_templates/cuda/ldsm.h> #include <tl_templates/cuda/threadblock_swizzle.h> #include <tl_templates/cuda/debug.h> extern "C" __global__ void __launch_bounds__(128 ) main_kernel (half_t * __restrict__ A, half_t * __restrict__ B, half_t * __restrict__ C) {extern __shared__ __align__(1024 ) uchar buf_dyn_shmem[];
同理,用户可以通过该步骤插入与CUDA编程一样的任意关于代码的打印调试。
使用 T.print 打印变量和 Buffer 调试 在 TileLang 中,为了排查程序在运行过程中的内部变量或中间结果是否符合预期,可以使用内置的 T.print 调试原语进行打印。它的使用方式与 Python 中的 print 类似,但运行环境是在 GPU Kernel 或者 CPU Kernel 中,因此要注意打印的线程上下文以及并发带来的输出顺序混乱,下面我们通过一些示例来展示如何使用 T.print 来打印 Buffer、变量等信息,以便在出现错误或结果不一致时进行排查,这些例子可以在testing/python/debug/test_tilelang_debug_print.py中找到:
1. 打印整个 Buffer 首先看一个最简单的例子,我们想要把一个分配到共享内存(shared memory)中的 Buffer 完整地打印出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 def debug_print_buffer (M=16 , N=16 ):"float16" @T.prim_func def program (Q: T.Buffer((M, N ), dtype ) ):with T.Kernel(4 , 4 , 2 , threads=128 * 2 ) as (bx, by, bz):print (shared_buf)"cuda" )
以上示例中:
T.alloc_shared([M, N], dtype) 分配了一个大小为 M*N 的共享内存 shared_buf。T.print(shared_buf) 会将该 Buffer 中的所有元素打印到 stdout。
需要注意的是,在 GPU 环境中,如果多个线程都执行了打印语句,最终的输出顺序可能是乱序的。对于简单调试而言,这一般足够了,但若要排除并发干扰,可以做一些条件限制(见下节)。
2. 条件性打印 当我们在大规模并发中打印过多信息时,输出往往会淹没我们所关心的内容。此时我们可以通过逻辑判断,只让指定的线程块或特定的线程进行打印。最常见的用法是只让一个 Block 或一个 Thread 执行打印逻辑,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def debug_print_buffer_conditional (M=16 , N=16 ):"float16" @T.prim_func def program (Q: T.Buffer((M, N ), dtype ) ):with T.Kernel(4 , 4 , 2 , threads=128 * 2 ) as (bx, by, bz):if bx == 0 and by == 0 and bz == 0 :print (shared_buf)"cuda" )
这样做可以显著减少打印信息量,让我们更加聚焦于单块或单线程的数据状态,该代码啥的输出为:
1 2 3 4 5 6 msg='buffer<shared_buf, float16>' BlockIdx=(0 , 0 , 0 ), ThreadIdx=(0 , 0 , 0 ): buffer=shared_buf, index=1 , dtype=half_t value=0.000000 'buffer<shared_buf, float16>' BlockIdx=(0 , 0 , 0 ), ThreadIdx=(0 , 0 , 0 ): buffer=shared_buf, index=2 , dtype=half_t value=0.000000 'buffer<shared_buf, float16>' BlockIdx=(0 , 0 , 0 ), ThreadIdx=(0 , 0 , 0 ): buffer=shared_buf, index=3 , dtype=half_t value=0.000000 'buffer<shared_buf, float16>' BlockIdx=(0 , 0 , 0 ), ThreadIdx=(0 , 0 , 0 ): buffer=shared_buf, index=4 , dtype=half_t value=0.000000 'buffer<shared_buf, float16>' BlockIdx=(0 , 0 , 0 ), ThreadIdx=(0 , 0 , 0 ): buffer=shared_buf, index=5 , dtype=half_t value=0.000000 'buffer<shared_buf, float16>' BlockIdx=(0 , 0 , 0 ), ThreadIdx=(0 , 0 , 0 ): buffer=shared_buf, index=6 , dtype=half_t value=0.000000
3. 打印线程索引或标量值 除了打印 Buffer,我们有时也需要打印简单的标量值(如线程块索引、线程索引、循环变量等)来确认它们是否按预期在变化。下面的示例在每个线程块中,只有线程内索引(tid)为 0 的线程会去打印 bx + by + bz:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def debug_print_value_conditional (M=16 , N=16 ):"float16" @T.prim_func def program (Q: T.Buffer((M, N ), dtype ) ):with T.Kernel(4 , 4 , 2 , threads=128 * 2 ) as (bx, by, bz):if tid == 0 :print (bx + by + bz)"cuda" )
4. 打印寄存器文件(fragment)内容 如果在 TileLang 中使用了 T.alloc_fragment(...) 分配类似寄存器文件(在 GPU 上类似 warp-level fragment)的空间,也可以直接调用 T.print 逐元素打印查看其状态。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def debug_print_register_files (M=16 , N=16 ):"float16" @T.prim_func def program (Q: T.Buffer((M, N ), dtype ) ):with T.Kernel(4 , 4 , 2 , threads=128 * 2 ) as (bx, by, bz):for i, j in T.Parallel(M, N):print (register_buf[i, j])"cuda" )
需要注意,如果不做任何条件限制,T.print 在并行遍历中会输出大量信息,可能会导致混乱,因此通常会配合条件语句做一些过滤或只打印部分感兴趣的元素。
5. 打印带消息前缀 有时我们需要在打印时附带一些提示信息,便于在混杂的控制台输出中快速定位。可以使用 msg 参数来指定提示内容。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 def debug_print_msg (M=16 , N=16 ):"float16" @T.prim_func def program (Q: T.Buffer((M, N ), dtype ) ):with T.Kernel(4 , 4 , 2 , threads=128 * 2 ) as (bx, by, bz):if tid == 0 :print (bx + by + bz, msg="hello world" )"cuda" )
这样就会在打印结果中包含类似 hello world: <value> 这样带前缀的信息,帮助我们区分不同打印语句产生的输出。
Comments