MLIR 是Google在2019年开源出来的编译框架。不久之前意外加了nihui大佬建的MLIR交流群,不过几个月过去了群里都没什么人说话,说明没人用MLIR(不是。现在刚好组里的老师对MLIR比较感兴趣让我进行一下调研,于是就有这篇比较简单的调研报告啦!
MLIR的全称是 Multi-Level Intermediate Representation. 其中的ML不是指Machine Learning,这一点容易让人误解,但现在的一些ML框架有些也在往MLIR靠,比如Tensorflow、Pytorch、ONNX都在写Dialect往MLIR上贴贴,Google的IREE是基于MLIR的End2End推理框架;ML也可以是Mid-Level,因为MLIR要解决Mid-Level IR的碎片化问题;ML也可以是摩尔定律,因为MLIR的Paper的标题是为了摩尔定律终结而诞生的编译器技术设施,当然也可以是Modular Library,现在看来,MLIR至少是一个优秀的编译器库。
一些你可以帮助你了解MLIR的资源:
目前,MLIR已经迁移到了LLVM下面进行维护。
如果想要引用MLIR,使用这一篇Paper:MLIR: A Compiler Infrastructure for the End of Moore’s Law
MLIR SIG 组每周都会有一次 public meeting,如果你有特定的主题想讨论或者有疑问,可以根据官网主页提供的方法在他们的文档里提出,有关如何加入会议的详细信息,请参阅官方网站上的文档。
一、Background
谁是MLIR的作者?
如果你和我一样曾经担心MLIR会成为Google众多开源到一半又被腰斩的工程之一,那么MLIR的作者是Chris Lattner这一事实可能会打消你的想法。Chris 同时也是LLVM项目的主要发起人和作者之一,Clang编译器的作者,在Apple工作了十年,是Apple开发用的Swift语言的作者。排个序的话,MLIR应该是Chris大佬继LLVM、CLang、Swift之后第四个伟大的项目。

网上瞎找的关于Chris的故事:2010 年的夏天,Chris Lattner 接到了一个不同寻常的任务:为 OS X 和 iOS 平台开发下一代新的编程语言。那时候乔布斯还在以带病之身掌控着庞大的苹果帝国,他是否参与了这个研发计划,我们不得而知,不过我想他至少应该知道此事,因为这个计划是高度机密的,只有极少数人知道,最初的执行者也只有一个人,那就是 Chris Lattner。
从 2010 年的 7 月起,克里斯(Chris)就开始了无休止的思考、设计、编程和调试,他用了近一年的时间实现了大部分基础语言结构,之后另一些语言专家加入进来持续改进。到了 2013 年,该项目成为了苹果开发工具组的重中之重,克里斯带领着他的团队逐步完成了一门全新语言的语法设计、编译器、运行时、框架、IDE 和文档等相关工作,并在 2014 年的 WWDC 大会上首次登台亮相便震惊了世界,这门语言的名字叫做:「Swift」。
根据克里斯个人博客(http://nondot.org/sabre/ )对 Swift 的描述,这门语言几乎是他凭借一己之力完成的。
克里斯毕业的时候正是苹果为了编译器焦头烂额的时候,因为苹果之前的软件产品都依赖于整条 GCC 编译链,而开源界的这帮大爷并不买苹果的帐,他们不愿意专门为了苹果公司的要求优化和改进 GCC 代码,所以苹果一怒之下将编译器后端直接替换为 LLVM,并且把克里斯招入麾下。克里斯进入了苹果之后如鱼得水,不仅大幅度优化和改进 LLVM 以适应 Objective-C 的语法变革和性能要求,同时发起了 CLang 项目,旨在全面替换 GCC。这个目标目前已经实现了,从 OS X10.9 和 XCode 5 开始,LLVM+GCC 已经被替换成了 LLVM+Clang。
Motivation
在MLIR的Paper里,主要是讲了两个场景,第一个场景是NN框架:
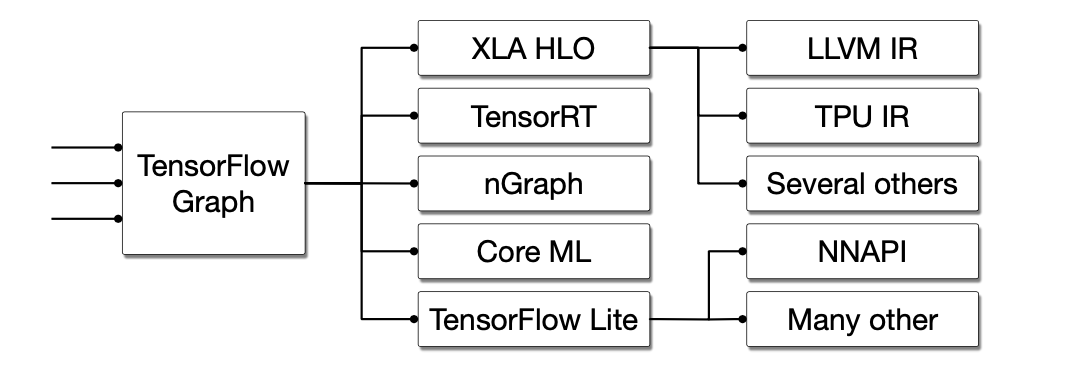
Work on MLIR began with a realization that modern machine learning frameworks are composed of many different compilers, graph technologies, and runtime systems.
比如说,对于Tensorflow来讲,他其实是有很多Compiler、Runtime System、graph technologies组成的。
一个Tensorflow的Graph被执行可以有若干条途径,例如可以直接通过Tensorflow Executor来调用一些手写的op-kernel函数;或者将TensorFlow Graph转化到自己的XLA HLO,由XLA HLO再转化到LLVM IR上调用CPU、GPU或者转化到TPU IR生成TPU代码执行;对于特定的后端硬件,可以转化到TensorRT、或者像是nGraph这样的针对特殊硬件优化过的编译工具来跑;或者转化到TFLite格式进一步调用NNAPI来完成模型的推理。
第二个场景是各种语言的编译器:
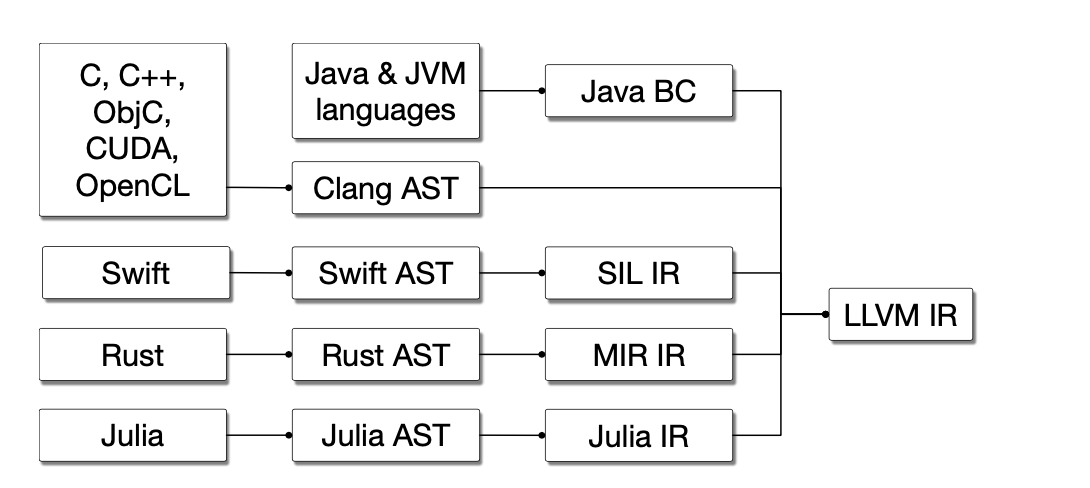
每个语言都会有自己的AST,除了AST以外这些语言还得有自己的IR来做language- specific optimization,但是他们的IR最后往往都会接到同样的后端,比如说LLVM IR上来做代码生成,来在不同的硬件上运行。这些语言专属的IR被叫做Mid-Level IR,而且不通语言自己的IR的优化会有重复的部分,但很难互相复用代码,重复造了很多轮子。
对于NN编译器来说,首先一个显而易见的问题是组合爆炸,就比如说TFGraph为了在TPU上跑,要写生成TPU IR的代码,在CPU上跑要写对接LLVM IR的代码,对接到TensorRT上又有其他的工作量,类似的,其他PyTorch这样的框架也需要做同样的事情,但是每个组织发布的自己的框架,比如Pytorch、TensorFlow、MXNet他们的IR设计都是不一样的,不同的IR之间的可迁移性差,这也就代表着大量重复的工作与人力的浪费,这个问题是一个软件的碎片化问题,MLIR的一个设计目的就是为这些DSL提供一种统一的中间表示;其次,各个层次之间的优化无法迁移,比如说在XLA HLO这个层面做了一些图优化,在LLVM IR阶段并不知道XLA HLO做了哪方面的优化,所以有一些优化方式可能会在不同的层级那边执行多次(嘛,我觉得这个问题还好,最后跑起来快就行了,编译慢点没事);最后,NN编译器的IR一般都是高层的计算图形式的IR,但是LLVM这些是基于三地址码的IR,他们的跨度比较大,这个转换过程带来的开销也会比较大。
最后,MLIR的这一篇Paper的标题是摩尔定律终结下的编译器基础架构,我理解的其含义是在摩尔定律终结,工艺已经到达临界的情况下,针对各种领域设计的DSA用的多了,异构系统的情况下的软件栈需要巨大的人力是一个很大的问题,而MLIR可以提供一种类似脚手架的存在,能够快速融合现有的编译器设计快速的打造软件生态。
二、使用CLion远程调试MLIR项目
最好的看代码的方法当然是打断点调试。为了不污染环境,MLIR是我在服务器的Docker环境下构建出来的,需要在本地远程连接调试,踩了一点坑,这部分如果有人有类似的问题,可以参考。
远程调试,一般我会考虑两种方案,一种是用VSCode的Remote SSH插件,远程连接上去看文件很方便,但是本地和远程的文件不同步,很容易乱;一般看代码和文件的时候喜欢用VSCode,在开发的过程中我喜欢用CLion,相当于是在本地开发然后通过SFTP把文件传到服务器上运行,就是环境配置起来有些麻烦。
其实本质上是用CLion远程调试LLVM项目。
首先,先把LLVM的代码Clone下来,并创建build目录来保存编译出来的内容:
1 | |
然后,使用CLion打开llvm-project/llvm这个文件夹,此时会根据llvm下的CMakeLists.txt来在本地构建系统,这不是我们期望看到的,可以参考CLion Full Remote Mode这一篇文章来配置远程环境:
https://www.jetbrains.com/help/clion/remote-projects-support.html
然后,为了编译MLIR,我们需要在Preference->Build,Execution,Deployment->CMake里,更改为远程设置,在CMAKE OPTIONS里填上:
1 | |
然后,把Build Directory换成llvm-project/build的绝对路径。
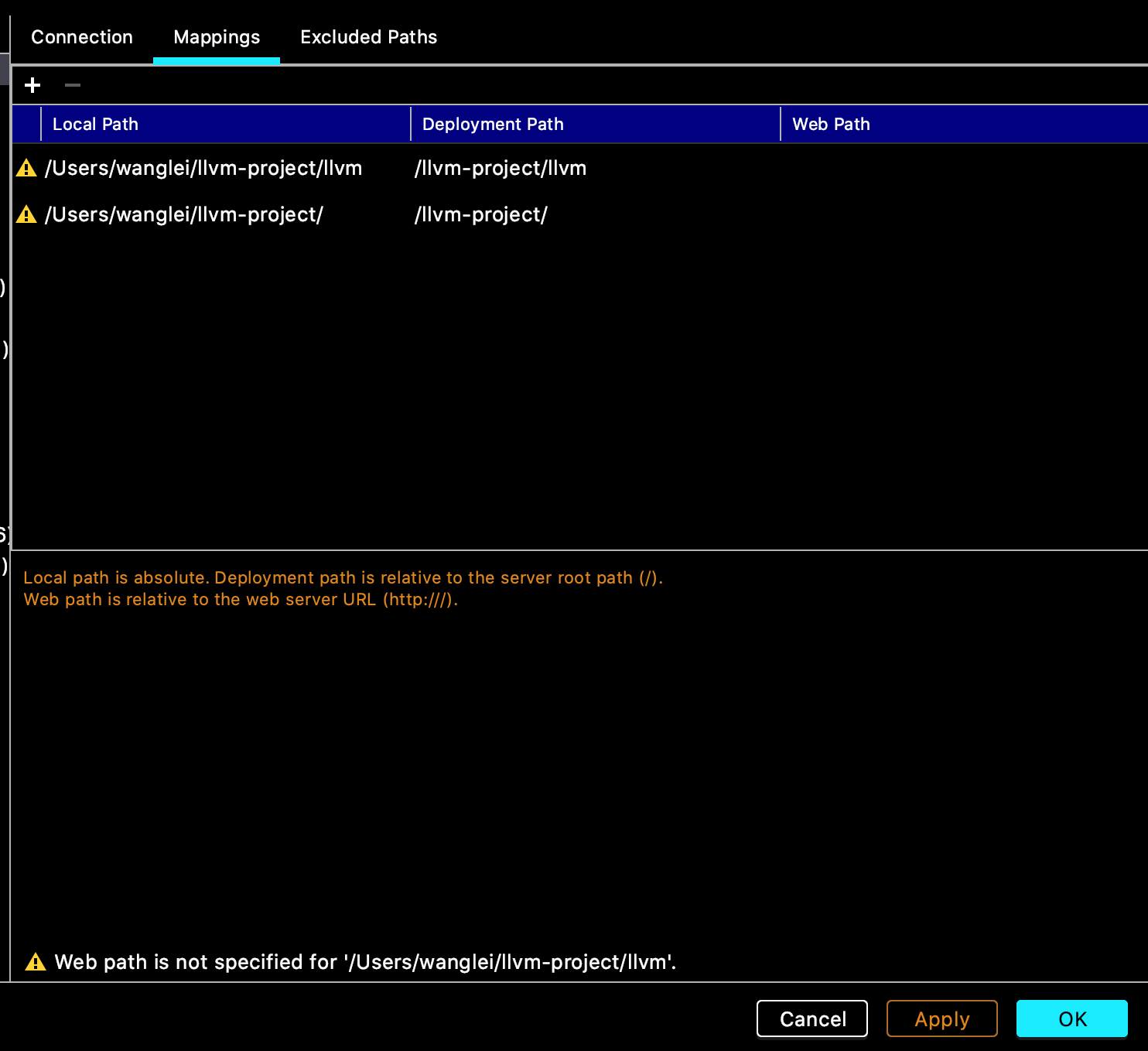
最后,在Deployment下添加这两个Mappings:
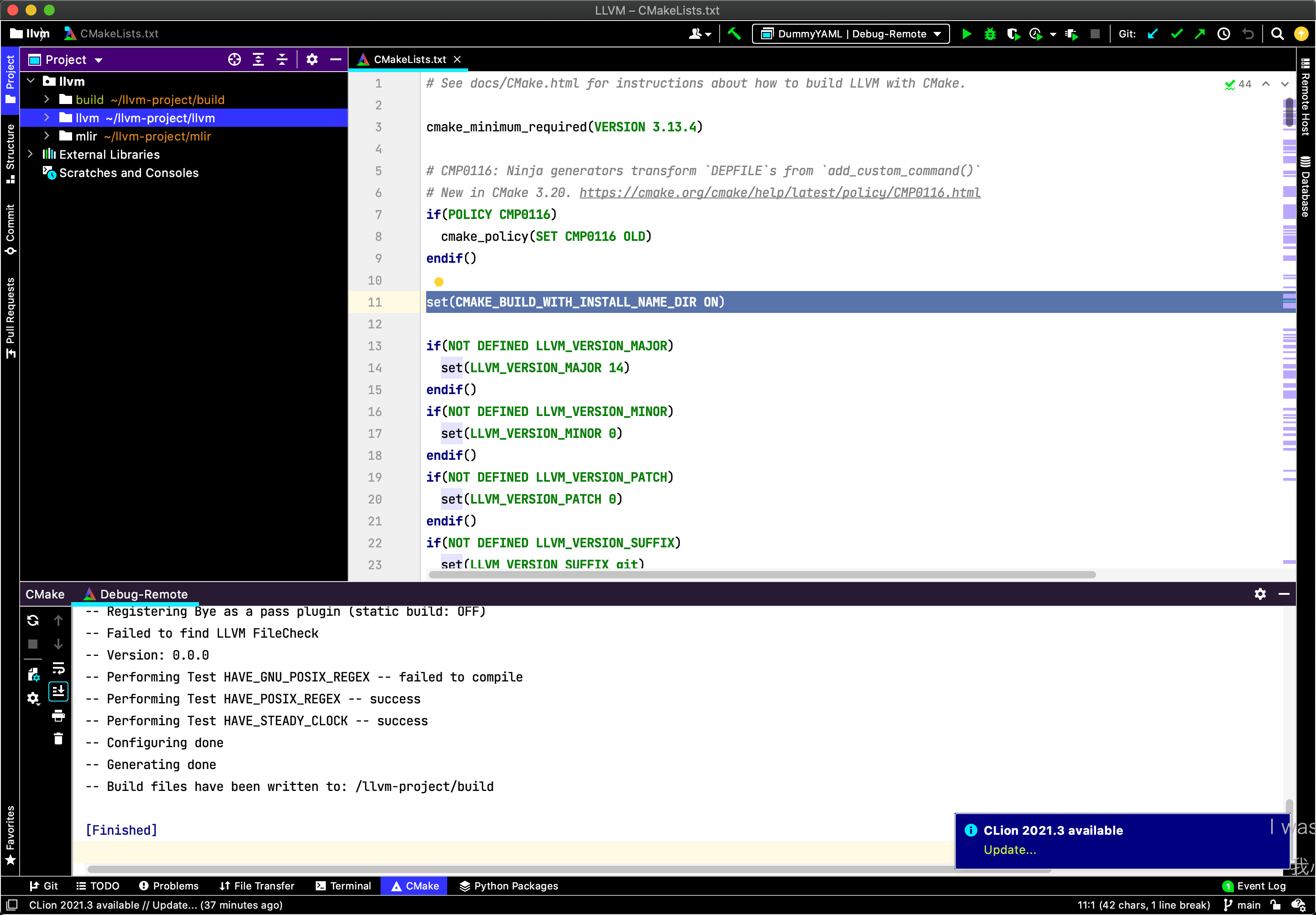
然后,CLion会自动在远程端进行MLIR的编译,编译完成之后的CLion页面如下:
之后我们就可以随意打断点调试了,跑个Toy Tutorial的Ch1康康:
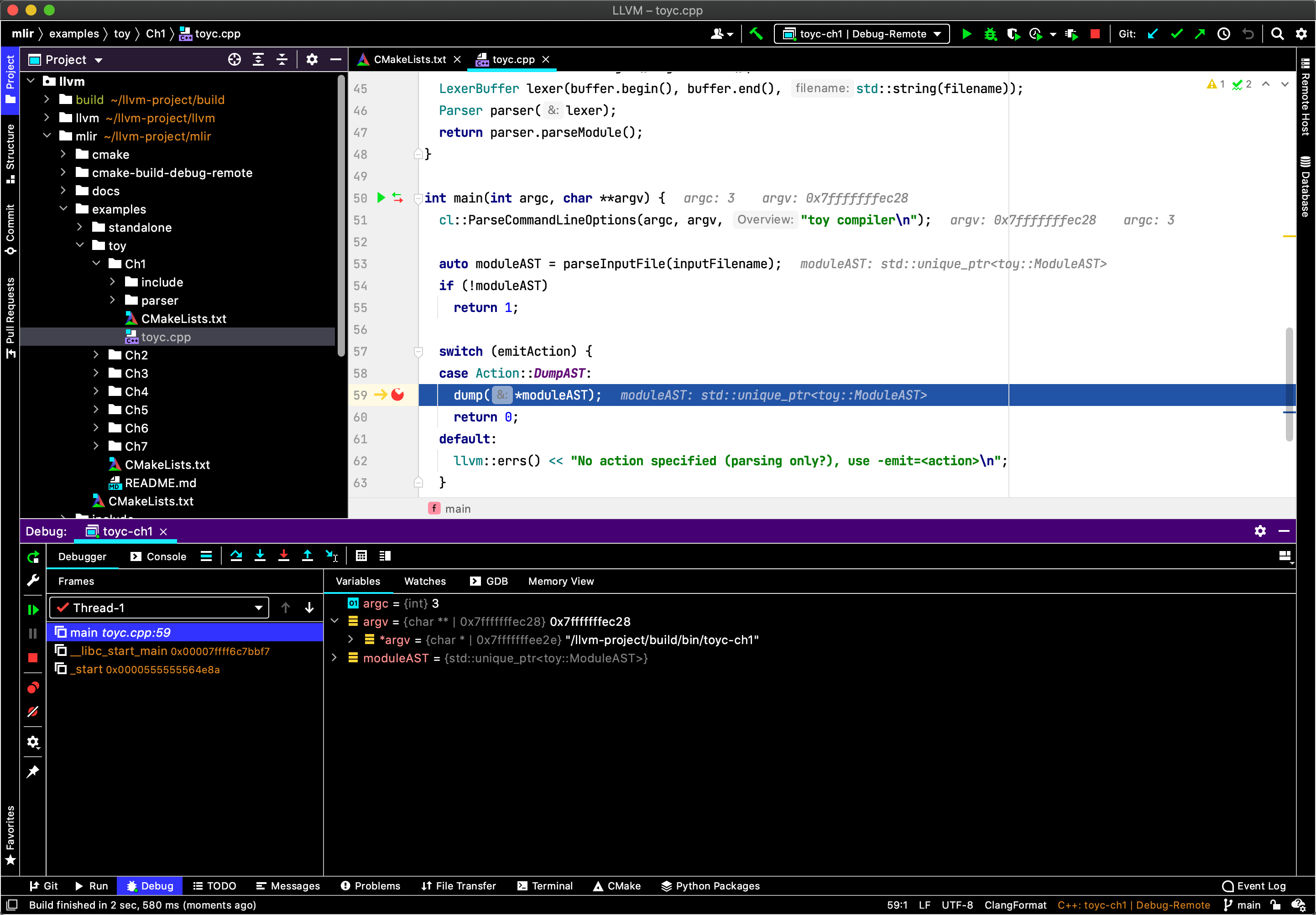
三、有关MLIR的细节
MLIR的表达式结构
在学习LLVM的时候,我们可以将一段C/C++程序使用CLang生成AST、生成LLVM IR与Pass优化,再到最后的代码生成来学习整个WorkFlow,但是目前来讲,官方没有提供C/C++代码生成MLIR的流程,虽然类似的工作有一些人来做:
- CLang AST -> MLIR : https://github.com/wsmoses/Polygeist
- C -> MLIR : https://github.com/wehu/c-mlir
还有MLIR官方也在推进的CIL,但是这些目前来讲都是野路子。MLIR提供了一个Toy语言,可以方便我们学习MLIR的流程,关于Toy语言详细,可以移步Tutorial.
这样跟随Toy Tutorial,我们把MLIR的一些细节过一下,从以.toy结尾的源文件到最后的Lowering需要经过如下的步骤:
.toy 文本文件 -> Toy AST -> MLIRGen -> Transformation -> Lowering -> JIT/LLVM IR.
AST
首先是AST部分,对于如下的Toy语言,没有用ast.toy这个文件,有点复杂而且是会抛异常的。如下来自Ch2的codegen.toy的例子能更好的贯穿文章:
1 | |
打印出该语言的Toy抽象语法树:
1 | |
不难察觉其和LLVM的抽象语法树的组织形式一样,一个文件对应一个Module,Module里包含若干Function,Function里包含若干基本块BasicBlock,BasicBlock里包含了若干条指令。
MLIRGen与Toy语言
.toy 文本文件 -> Toy AST -> MLIRGen -> Transformation -> Lowering -> JIT/LLVM IR.
MLIR的语言详细参考官方文档中的 Lang Ref : https://mlir.llvm.org/docs/LangRef/
其根本上是一个类似图的数据结构(其实是SSA,不过SSA的Define和Use关系构成了图),节点就是Operations,边就是Value.每个Value可以是Operation的返回值或者是Block的参数,Operations被包含在Blocks里,Block包含在Regions里,Regions包含在Operations里,如此往复,生生不息。Operations顾名思义可以代表很多内容,高层次比如说函数定义、函数调用、内存分配、进程创建;低层次比如说硬件专属的指令,配置寄存器和逻辑门(应该是指CIRCT这样的HLS项目),这些OP可以被我们随意的扩充。
ch2 ../../mlir/test/Examples/Toy/Ch2/codegen.toy -emit=mlir -mlir-print-debuginfo
即可将之前的codegen.toy文件转化正MLIR:
1 | |
单独拎出一句来简单看一下MLIR的表达式结构:
1 | |
显而易见的是%0是表达式的返回值,其也是以一种和LLVM IR一样递增的临时寄存器的形式存在,但是和LLVM IR不一样的是,LLVM的Basic Block本身会占用一个临时寄存器号,BasicBlock内部的临时寄存器是从%1开始编号的,不同于MLIR。
toy.transpose其中的toy类似于命名空间,算是Dialect的名字,transpose是OP的名字。
%arg0 : tensor<*xf64>是参数列表,前者表示参数的名字,后者表示参数的类型。
to tensor<*xf64>表示的是输出参数的类型。
loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:10)是在添加了-mlir-print-debuginfo之后生成的调试信息,表示该行表达式是从源代码的何处产生的。
你可能会疑惑,在有些tutorial里你看到的ir可能是这样的:
1 | |
这其实同一种表示不同的打印形式,毕竟这个打出来的IR是方便人来看的,在MLIR里可以非常方便的使用TableGen(MLIR专门设计的一个DSL)来调整这些输出,比如在我现在的的Project里,Ops.td里定义的Transpose的Operation如下:
1 | |
其中的assemblyFormat就是输出的格式,可以看到我们的输出与他的内容是一一对应的,只要更改每个OP这里的内容就可以实现输出的MLIR的格式,具体怎样调整,有哪些关键字,请参考Declarative Assembly Format。从这里就可以看出MLIR的可操作性非常强!
说回Toy Dialect,在上述源代码中我们可以看到该语言至少内置了诸如transpose,print,constant这一类的Operation,怎么定义或者扩展呢?在Tutorial的第二节里有讲,第一种方法是基于奇异递归模板模式(Curiously Recurring Template Pattern),用C++来继承mlir::Op的创建方案,另一种是使用ODS( Operation Definition Specification,基于LLVM专门设计的一个DSL TableGen实现)来快速的给出各种OP的定义,ODS的语法参考OpDefinitions,使用如下命令查看ods转化成的cpp文件内容,其中-gen-op-defs、-gen-op-decls分别对应着生成的定义和声明:
1 | |
简单看一下Ops.td里的AddOp的定义:
1 | |
显而易见的是声明的头部里有op在dialect里的name,“constant”,summary和description是自动生成文档用的。
arguments 是输入的参数,ins表示的是inputs,两个都是Float64的Tensor,加了$的两个表示输入的变量,tablegen会自动生成获取两个变量的方法:
1 | |
results是输出的内容,outs表示的是outputs,是一个Float64的Tensor。
parser和printer是用来指定自定义的mlir的文本输出方式,和前文中提到的assemblyFormat作用应该是类似的。
builders是指明了构造器,如果像上文中那样写的话,最后生成的构造器有三个:
1 | |
还有一些没有写的,比如说验证参数正确性的verifier等等,这里只是做简单的survey就不要继续往下挖。总之,TableGen能帮助我们缩短构建一个新的DSL,添加OP、或者是添加一个新的后端的时间,这一点已经在LLVM里得到了验证。
那怎么创建一个Dialect?需要Follow官方的文档:https://mlir.llvm.org/docs/Tutorials/CreatingADialect/ 粗略扫了一下封装的很好,改动的部分十分少。
Transformation
.toy 文本文件 -> Toy AST -> MLIRGen -> Transformation -> Lowering -> JIT/LLVM IR.
接下来是Transformation,既然是IR当然会有Pass来做优化啦。MLIR的特点是Dialect是一个没有那么Low Level的IR,比如说:
1 | |
这样的函数,input的矩阵经过两次transpose操作,那么显然它最后的结果仍然是它本身,可以把这两个transpose都优化掉,但是如果我们将这段mlir代码lowering到底层,展开成for循环的形式则发现这两个transpose可以优化的难度很大:
1 | |
MLIR使用和LLVM一样的PassManager来管理Pass,而对于写Pass的方法,MLIR又提供了两种方案。比如对于刚才双重transpose的问题,我们可以通过重写MLIR的Canonicalizer里的MatchAndRewrite方法首先,顾名思义,他就是匹配模式然后重写,具体的代码如下:
1 | |
大概的含义是,对于每个TransposeOp,找到他的输入,如果他的输入也是由一个TransposeOp定义的,那么就调用replaceOp函数来将这两个transpose消除,具体如何消除需要看replaceOp的内容。
1 | |
根据字面意思,这个函数的作用是会将输入op的result,也就是%1 = toy.transpose(%0 : tensor<*xf64>) to tensor<*xf64>中的%1替换成一组值,而这一组值是transposeInputOp.getOperand()也就是%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>中的%arg0,然后将原来的op删除。但是如此的话,经过这个pass优化完的mlir长这个样子:
1 | |
这可以理解,因为replaceOp只清除了最下面的op,中间的operation应该如何删除?显然这是一条死代码,MLIR的CanonicalizerPass会自动的删除MLIR的死代码,所以最后输出的结果如下:
1 | |
除了这种用C++来手撸Pass的方法,MLIR还提供了一种叫做DRR(Declarative, rule-based pattern-match and rewrite)的声明式的方法来快速的完成Pass的编写从而不需要care具体的API,其实也是TableGen的语法,有关DRR的细节,优点和局限具体参考DeclarativeRewrites这一节。
MLIR的文档里提到,不同的Dialect之间有很多的Pass具有重复的部分,可能对于这种transpose消除的操作,toy这个语言需要写这样的代码,另一个语言也需要重复实现不少相同的内容,为了更好的复用,MLIR提供了一种叫Interface的解决方案,Inteface分为Dialect和Op两类,其中后者的粒度更细。比如Ch4里演示的内置的DialectInlinerinterface和ShapeInferenceOpInterface,而且也有基于TableGen的设计方法!
1 | |
Lowering
.toy 文本文件 -> Toy AST -> MLIRGen -> Transformation -> Lowering -> JIT/LLVM IR.
把toy的dialect转化成llvm ir就是一个lowering的过程,但是在MLIR的设计上,一个dialect可以背lower到多个dialect上,比如ch5的例子就将toy dialect中的transpose下降到了Affine Dialect、其他的比如print可以先保持在toy dialect,之后可以lower到llvm dialect上来实现,常数lower到arith dialect、还有memref dialect来管理内存。言下之意就是MLIR在lower的过程中可以支持部分代码lower到不同的dialect,以及不同的dialect在MLIR里可以共存。
Affine的意思是仿射变换,对于矩阵这种高纬度的运算适合lower到affine上做优化,但是为啥合适?可能需要参考一些多面体编程框架有关的知识,有关Affine Dialect详细,请参考:https://mlir.llvm.org/docs/Dialects/Affine/
Arith是用来做基本的一元两元三元的数学运算,比如加减乘除求最大值最小值等。
以及Dialects里列出了很多现有的Dialect,对于如下的toy dialect:
1 | |
部分Lowering到Affine并通过Pass来优化的最终结果是:
1 | |
当然也可以全都Lowering到LLVM上:
1 | |
Lower的过程是需要我们针对toy里的Operation来写Lower的代码,,感觉这个工作量也是非常爆炸的吧,不知道有没有自动化的方法?
Codegen
.toy 文本文件 -> Toy AST -> MLIRGen -> Transformation -> Lowering -> JIT/LLVM IR.
到这里,就可以做codegen了,生成LLVM IR或者是用LLVM JIT来执行程序,开了optimization之后的LLVM IR被优化为:
1 | |
四、已经使用MLIR的项目
从MLIR官方给的toy语言里我们能够感觉到在设计一个新的DSL其带来的便利,但是我更关心的是在其他一些领域比如说NN编译,或者一些更妙的地方MLIR能发挥什么作用?有关MLIR具体可以解决什么样的问题,解决的怎么样了,需要看一下当下使用MLIR的一些项目。
但是,MLIR刚刚起步,很多接口也在不停的变化,所以依托MLIR开发的项目也都是比较新的,文档比较少,功能还不是很丰富,都是处于苦逼的造轮子阶段。
CIRCT - Circuit IR Compilers and Tools
项目地址:https://github.com/llvm/circt
Talks:
顾名思义,CIRCT是一个高层次综合的工具。值得注意的是,CIRCT的主要发起者还是Chris,并且FIRRTL的作者也在参与这个项目,此外还有Sifive、Xilinx、Microsoft这些大厂来做支持,MLIR在里面发挥了么作用呢?也是类似于一统IR的作用,在CIRCT的文档里提到,现有的很多的EDA工具都是以Verilog IR为主的,但是这个上世纪的语言显然有太多的缺点了,于是这个项目希望用MLIR来统一,具体怎么做?因为对这个不太感兴趣所以没有编译出来跑个Demo,就来看一下一个由法斯特豪斯大佬给的例子吧:https://www.bilibili.com/video/BV1UV411U7Nk.
这里我直接贴个他们的视频里的图片:
con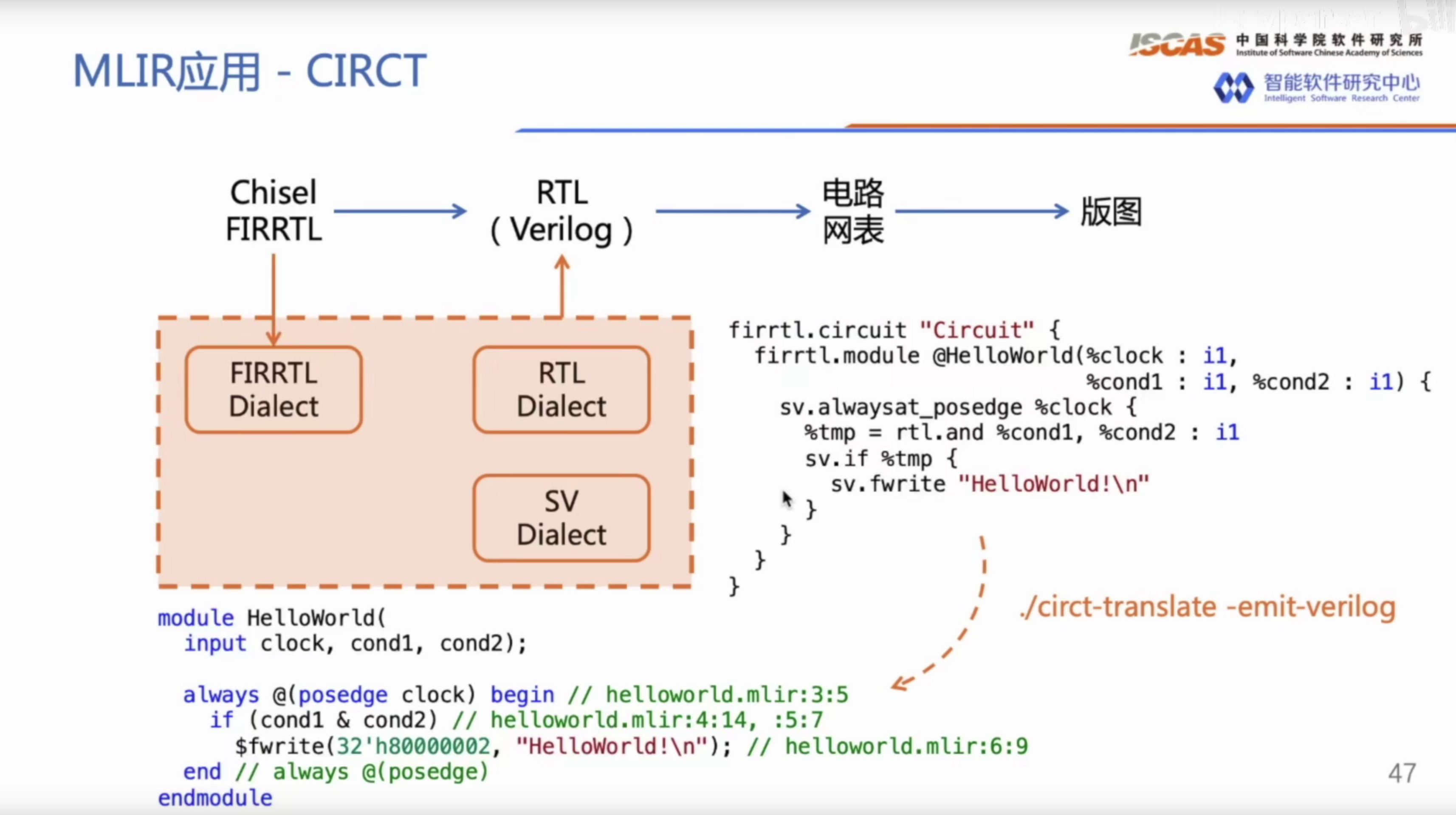
看起来,CIRCT至少提供了RTL(rtl.and)、FIRRTL(firth.circuit)、SystemVerilog(sv.fwrite)这三个Dialect,但最后还不是要lowering到Verilog上嘛…..
但是,我对高层次综合这个领域这个看法还是比较消极的,主要是他们最后还是都得生成verilog去综合而不是有自己的综合器,虽然使用高层次综合能在一定程度上增加开发的效率,但是对于整个IC设计的Workflow来说,前端的设计只占其中的一部分,后端的测试、验证等等工作用到的很多EDA软件对于生成的可读性不是很好的verilog代码来说反而是增加了难度,其次,前端设计也不是一些dirty work,反而是一些对延迟敏感的clean work,一般来讲,手写verilog RTL都能获得最好的性能,所以核心还是Synopsys这些厂商给不给综合器的支持。
IREE Intermediate Representation Execution Environment
Presentations and Talks
- 2021-06-09: IREE Runtime Design Tech Talk (recording and slides)
- 2020-08-20: IREE CodeGen: MLIR Open Design Meeting Presentation (recording and slides)
- 2020-03-18: Interactive HAL IR Walkthrough (recording)
- 2020-01-31: End-to-end MLIR Workflow in IREE: MLIR Open Design Meeting Presentation (recording and slides)
这是Google自家做的一个端到端的基于MLIR的推理项目,根据其框架图:
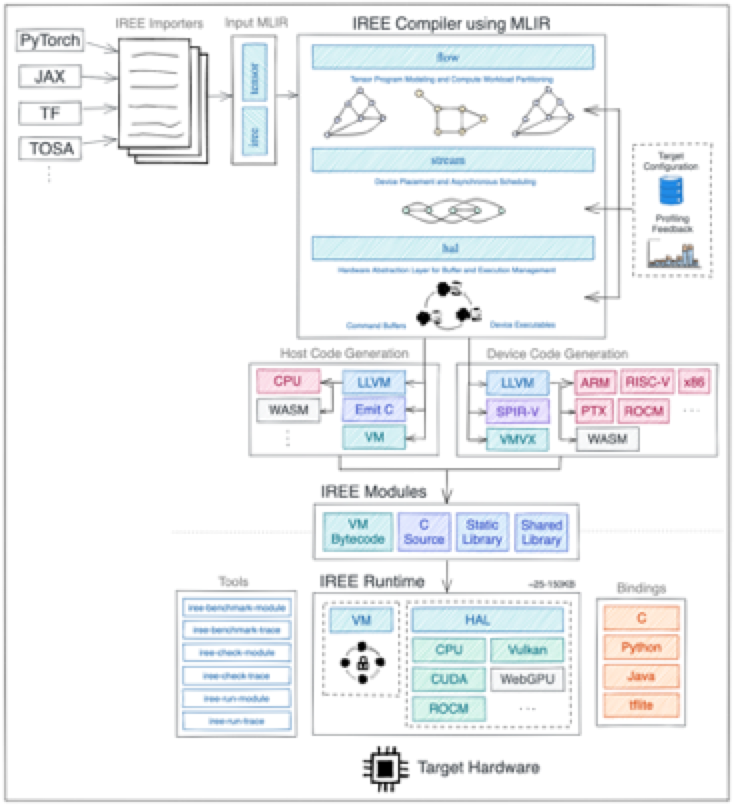
目测他是由以下几个成分:
- 把输入的Graph转化成XLA HLO Dialect
- 将HLO Dialect Lower到Flow Dialect,Flow 这一层来做算子的切分
- 继续Lower到HAL Dialect、完成与硬件相关的转换与优化
- VM Dialect,看他官方的文档的描述,是一个隔离硬件与软件的虚拟机IR

但是现在来看只能支持Tensorflow和JAX的模型,现在ONNX和Torch分别由ONNX-MLIR和Torch-MLIR这两个项目在做。并且,我很好奇对于同样的网络,基于MLIR的端到端推理速度会比现在的NN推理框架要快吗?因为调研到现在来看,MLIR似乎侧重于减轻开发的工作量,不知道性能是怎么样的?
在IREE的项目里面,给了几个CoLab的例子,居 然 还 可 以 跑 训 练,但是对于一些推理的Task没有贴上时间,该项目现在还在早期阶段,优先支持的是vulkan-spirv,用于mobile gpu,兼顾cpu和cuda。
ONNX/Torch-MLIR
虽然MLIR出身于TensorFlow,并且官方提供了tensorflow的Dialect以及HLO的dialect,但是像是FaceBook的Pytorch现在也有torch-mlir以及微软的ONNX也有onnx-mlir这些项目。
https://github.com/onnx/onnx-mlir
https://github.com/llvm/torch-mlir
基本上是这些框架在发力为MLIR贡献生态,比如说ONNX Dialect、Krnl Dialect,也可以实现端到端的推理,但是还是一样,对于这些项目目前都是处于能跑,对于性能来讲都还在慢慢提升的阶段。
TOSA - Tensor Operator Set Architecture Dialect
TOSA应该说是ARM推出的一个算子规范(怎么听起来有ONNX那个味道了,感兴趣的可以去MLIR的官网下载TOSA SPEC文件,定义了八十六页的规范,但支持的算子是否足够使用也不明朗,在文档的开头写到希望这些主流框架的模型里的算子可以被在TOSA里被表示,目前来讲TF的mlho dialect已经可以转到TOSA Dialect,像Pytorch的话,也正在做torch-mlir到tosa dialect支持。

Linalg Dialect
针对ML编译器设计的中上层IR?知乎里有过讨论:
https://www.zhihu.com/question/442964082/answer/1718928279
总结
刚刚接触MLIR的时候看了很多Talk和博客,我一直不明白MLIR的定位究竟是什么。从Chris大神一直在说的解决软件碎片化的角度来看,各大AI框架、软件框架之间的碎片化慢慢得转化成了MLIR内部各种Dialect的碎片化,再依托MLIR各种Dialect都属于同一种语言可以混用的特性来减轻这种碎片化带来的影响,虽然上一个说要解决碎片化的框架ONNX会多出一些胶水op,反而起到了一些反作用,但是MLIR逐级向下的策略不会出现A->B->A这样的情况。
再或者,以前的AI框架诸如Tengine、NCNN这些是根据指令和高层次的IR的意图来手写算子,当出现了新的指令架构或者新的DSA(这个在当下的需求越来越多,因为工艺很难上去了,各种DSA就被设计出来),需要耗费人力来对接后端,而MLIR试图缩减这些人力的开销,但是MLIR现在还是苦逼的造轮子阶段,比如大家都在给MLIR搭建生态,写Dialect,现在肝的内容甚至要比手写还要多一点。但是当MLIR做的比较完善之后,可能只需要写写Schedule和Pass就能把对接新后端的工作给做了!这也是MLIR论文的标题写到摩尔定律终结的原因吧,如果说MLIR可以很轻松的为新出现的DSA编写算子库的话,那就比较舒服了。
总之,至少MLIR绝对是一个优秀的编译器库,他由已经成神的拥有数十年编译器开发经验的Chris组织代码结构,模块化和可扩展性做的极度优秀,也许MLIR从TensorFlow转换到LLVM项目下维护之后,他就更像是一个开发组件了。但如果把MLIR类比为编译器领域的ONNX,这条路看起来还不太明朗,至少我没有感觉到很便利,根据TVM的经验,ML的编译器有三个核心问题,分别是AutoTensorize,充分利用硬件的指令;AutoSchedule,本质是各种循环变换;AutoTiling,提高Cache命中率降低访存开销,除了Schedule有类似Affine这样的Dialect来做(大概可以吧,其他两个问题的答案似乎在MLIR里都没有找到,我只能希望MLIR不要走上ONNX的老路,真正的解决碎片化,成为一个能够真正一统江湖的IR。
nihui建的mlir交流群:677104663(可能不活跃就是
Comments