这篇是我在第一次参与的组会上分享的顶会论文,是我认识的一位博士发表的,其标题的含义大致是为具有鲁棒性的,由神经网络架构搜索出来的网络设计的加速器结构:
《NASGuard: A Novel Accelerator Architecture for Robust Neural Architecture Search (NAS) Networks》
总结:Robust NAS 是研究人员用神经网络架构搜索的方式来研究神经网络的结构本身针对神经网络模型的对抗训练攻击的防御性而产生的。虽然本篇文章是和 NAS 相关的论文,但不是针对 NAS 漫长的训练过程设计的加速器,而是作者总结近年来典型的 Robust NAS 网络,发现其存在较多的多分支结构、分支与分支之间存在较多的互联情况等问题,这些问题的存在使得常见的加速器的PE阵列资源利用率变得不高,以及因为互联造成了并行度的限制,导致需要多次与外存交互。这篇论文提出了一个分支调度电路、以及一个权重等数据的 prefetch 缓存电路,结合编译器来自动分配PE阵列的资源、提前将需要的数据进行缓存,是一个以面积换效率的工作。
本文我比较感兴趣的点是作者在对设计的电路进行评估的时候使用的一些方法;例如评估系统的各个模块的面积占用使用的是Synopsys DC;电路仿真与性能评估使用的是一个叫 MAESTRO 的模拟器;这些方法的指导我觉得是很有意义的,找到了关于 MAESTRO 的两篇论文,其中一篇还与 NVDLA 有关,下周看看。
- 什么是具有鲁棒性的NAS网络?
在这篇论文的引用文献里,我找到了最开始出现Robust NAS这个名词的论文,其摘要里有这样一段:
Since then, extensive efforts have been devoted to enhancing the robustness of deep networks via specialized learning al- gorithms and loss functions. In this work, we take an archi- tectural perspective and investigate the patterns of network architectures that are resilient to adversarial attacks
《When NAS Meets Robustness: In Search of Robust Architectures against Adversarial Attacks 》
可以看到Robust NAS是与网络对抗攻击相关的研究,该文章之前的研究者提出了大量对抗这种攻击手段的方法,其中的主要关注点包括算损失/正则化函数的改进,图像预处理等等,而这篇文章的idea是想研究神经网络结构本身对其抵御对抗样本的影响,使用神经网络架构搜索的方式来搜索一个鲁棒性比较好的架构。这个找出来的网络就叫做 Robust Neural Networks,中文翻译过来应该是具有好的鲁棒性的网络。
但是可以预见这个运算需要的算力肯定十分庞大,因为NAS需要的时间本来就很长,为了得到一个鲁棒性好的网络,还需要引入对抗训练。当然这篇文章也用了一些方法来减少了运算量。
(但是这篇论文看下来,发现该文章不是NAS的训练过程做加速,主要还是对搜索之后的生成的网络推理过程做加速),首先文章列举了自NAS应用到对抗防御领域来的八篇典型的网络。

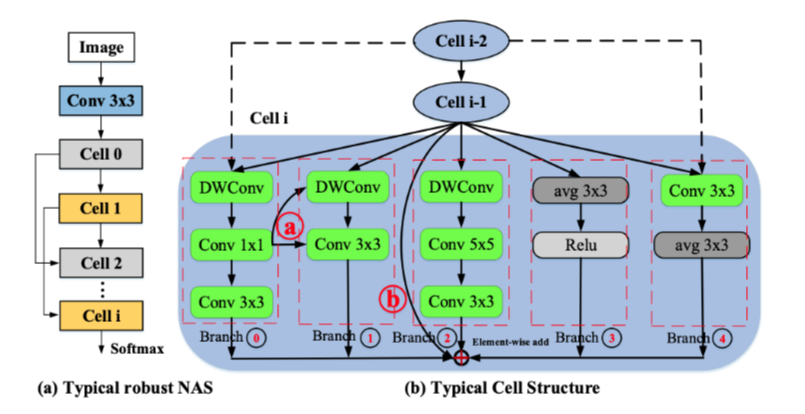
作者分析了一下最终由 NAS 搜索出来的网络的结构,每个cell都是一个搜索空间:
最后搜索出来的最优的网络内部连接方式可能如右图,是一个多分枝的情况:作者观察在上述的典型的Robust NAS网络中,这种结构多分枝结构的出现频率要高于35%,而与之相关的权重高达61%
Current DNN accelerators usually adopt monolithic systolic array architecture to execute each DNN layer serially. They usually contain a two-dimensional PE array and hierarchical on-chip buffers [38], [39], [41], [45]. The systolic array architecture, which is represented by Google TPU [37], cannot efficiently tap into the parallelism of robust NAS networks
但是现有的很多典型的加速器设计都是通过大块的脉动阵列来串行的执行每个层,不能有效的挖掘出这些多分枝的并行性。例如在Google TPU上运行该网络,PE阵列的使用率只有30%~64.5%。
虽然像DaDiannao这种多核的体系结构可以解决多分枝并行运算的问题,但是在这些典型的网络的多分枝结构中会有20%~35%的几率出现右图里的a点的互联情况,这种不常见的网络结构没有在这些处理器中被考虑到(这部分的理解有待商榷),会限制加速器的性能。
本文最后设计的加速器结构如图:
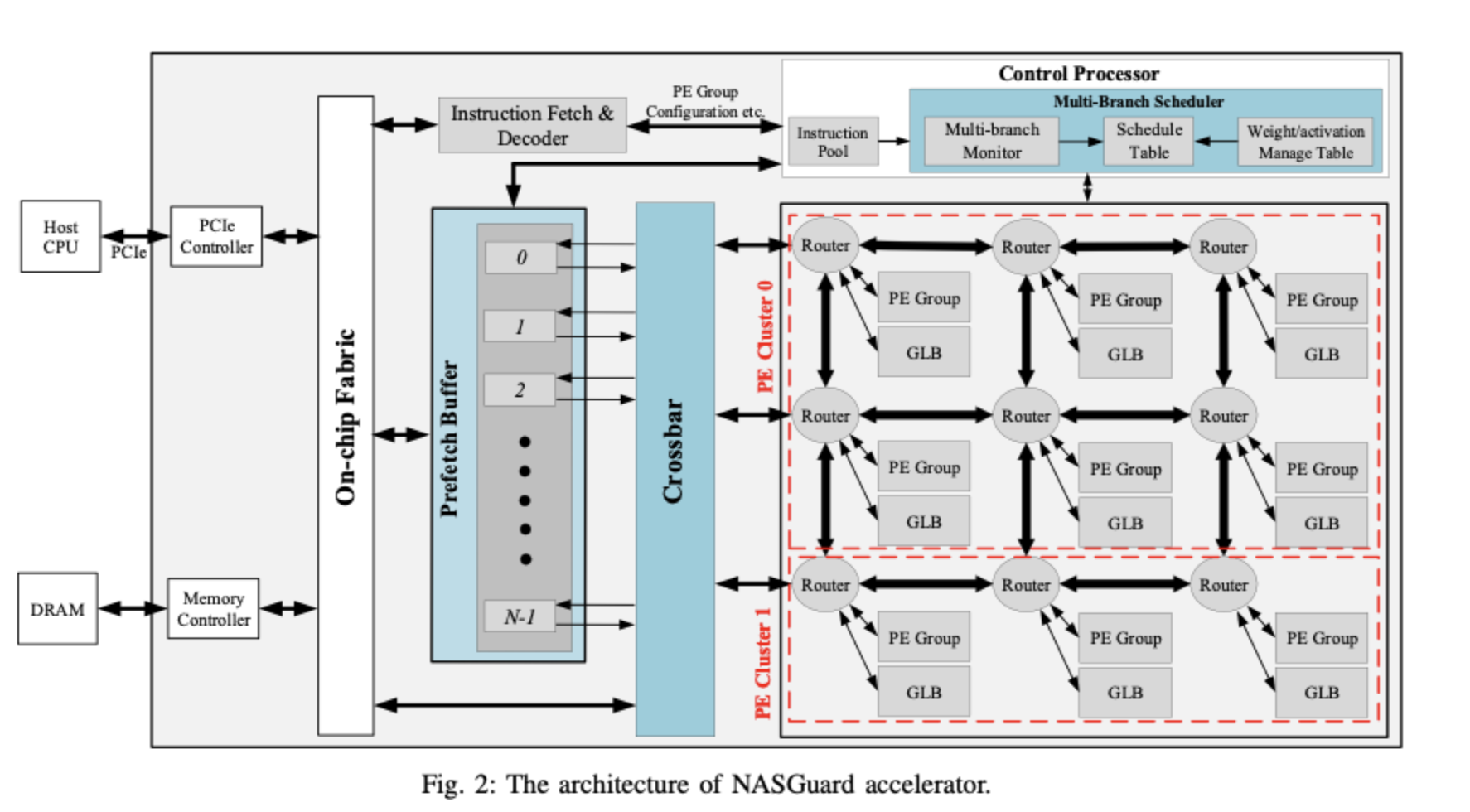
蓝色标注的两块是多分支调度电路和prefecth缓存,其他的PE阵列、取指等设计根据作者描述都是典型的设计,论文最后的验证就是就是首先在典型的电路上分别进行若干Robust NAS 最后搜索出来的网络进行推理,加分别上多分支调度和Prefetch电路观察加速比。
多分支调度电路(Multi-branch Scheduler)有三个主要的组成部分:调度表(scheduling tables)、权重/激活管理表(weight/activation management tables)、分支监视器(branch monitor)。
调度表文章没有详细阐述他的结构,我觉得应该是一个寄存器。用来记录为当前运算的cell分配了哪些PE的资源的?可能是由Compiler进行提前预测,然后由Runtime动态调整的。
分支监视器是设计中的一个很神奇的东西,他通过一个叫做(topolgy-aware prediction)的东西,来预测接下来的执行状态,动态的为每个分支分配PE资源,提高PE的利用率(当然读完发现这部分也是在Compiler阶段做的)。
所以我个人的理解是,Compiler会根据网络的结构生成一个推荐的PE阵列的调度顺序,由Runtime来存到Schedule Table内部,分支检测器根据Schedule Table的内容分配 PE 的资源,同时更新权重管理表与激活管理表,这两个表如果检测到当前运算的分支的权重数据的索引接近预存入的点的时候将触发相应的操作,进行运算的权重等数据读入prefetch缓存(其中prefetch缓存分了三个存储层次)。
最后,本文章的对比是在前文的 Fig.2 这个体系结构中,将蓝色标注的两部分电路去除所得到的常见加速器结构与加上分支调度电路、加上Prefetch电路的加速器结构进行的对比。
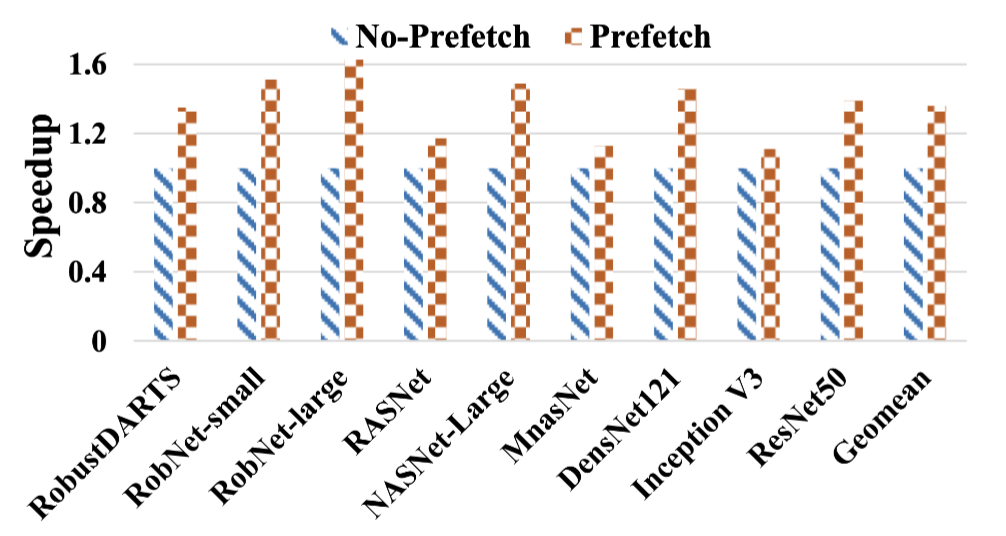
结论如图,这是在几个典型网络上的加速比,此外还可以提高PE的数量来做到进一步的加速:
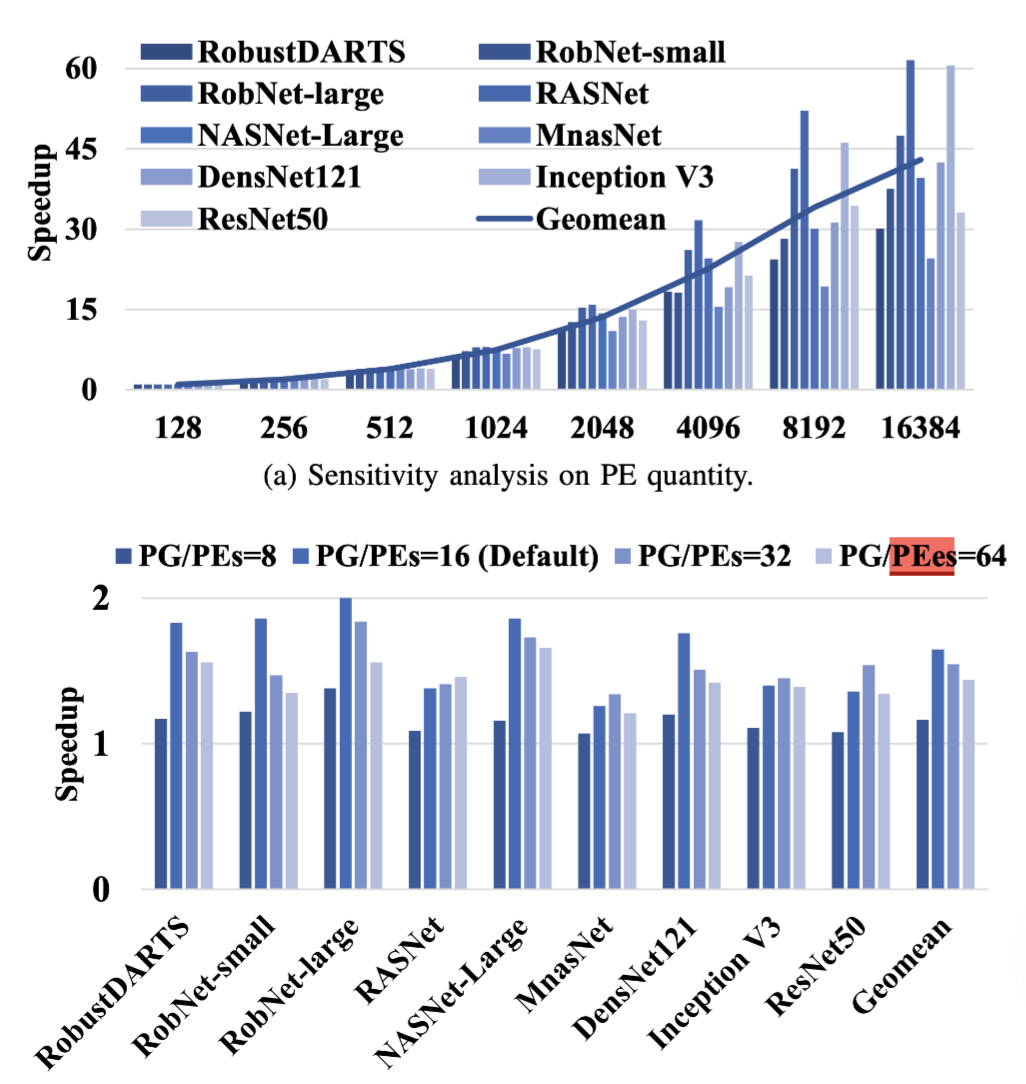
但是在 MnasNet 上的效果不是很明显,主要是该网络的深度Conv太多了,限制了PE的利用率,这个本设计也是没有解决。
虽然获得了一定的效果,但是也是用面积换来的:
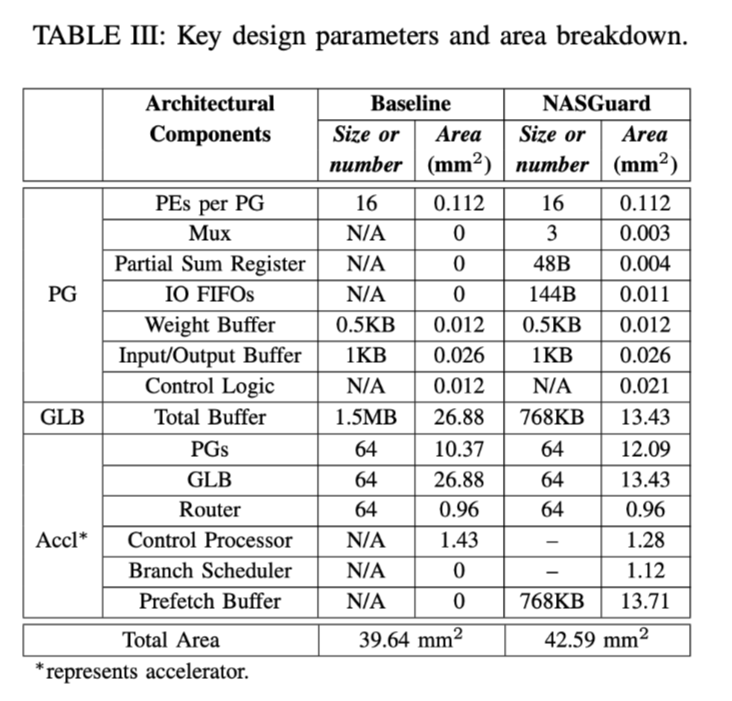
此外,他的各种数据得到的方式是由一个开源的模拟器MAESTRO得出的。
一些名词的解释:
GLB:
a GLB is paired with each PG and records weights and input/output activation values from the off-chip memory or prefetch buffer
GLB 应该是指 Global Buffer,每个 PE 阵列都会有的一个片上 SRAM 缓存,这部分设计可以参考 Eyeriss v1。
Crossbar:https://www.zhihu.com/question/31049944/answer/55536358
MAESTRO:《Understanding Reuse, Performance, and Hardware Cost of DNN Dataflows: A Data-Centric Approach》
本文提出了一种Data-Centric方法,并设计了MAESTRO(Modeling Accelerator Efficiency via Spatio-Temporal Reuse and Occupancy)用于在给定DNN模型和硬件配置时,不同数据流对运行时间和功耗的影响。
这个我觉得超厉害,一种模拟器。
Comments