前言
NVDLA的软件栈主要分为两个部分:Compiler与Runtime,由于Compiler与硬件无关,所以可以在我们自己的开发机器上编译运行调试,理解起来也较为方便;而Runtime与硬件有关,调试非常困难,官方提供的预构建的文件又都是针对64位ARM/RISC的操作系统,这对没有合适的板卡,即仅搭载了32位处理器的ZYNQ 7000系列的开发板上编译Runtime带来了很多难以解决的问题。
Loadable文件是两者之间通信的媒介,本文记述一下Loadable文件的组织结构和解析方法,既然不能吃官方给的饭,那么可以试一试自己在SOC上做一份调度的算法,解读Loadable文件就是第一步。
Github Repo:https://github.com/LeiWang1999/nvdla-parser
首先,我们使用nvdla_compiler编译生成一个loadable文件,你可以在这个连接下载到预先编译好的文件,里面已经包含了生成的fast-math.loadable:
root@96c1b26765d1:/usr/local/nvdla# ./nvdla_compiler --prototxt lenet-mnist-caffe/lenet/lenet.prototxt --caffemodel lenet-mnist-caffe/lenet/lenet.caffemodel --cprecision int8 --calibtable lenet-mnist-caffe/lenet.int8.json --configtarget nv_small
creating new wisdom context...
opening wisdom context...
parsing caffe network...
libnvdla<3> mark prob
Marking total 1 outputs
parsing calibration table...
attaching parsed network to the wisdom...
compiling profile "fast-math"... config "nv_small"...
closing wisdom context...简单介绍使用到的参数:
fast-math是什么?
在编译期间可以做一些硬件无关的优化,例如算子融合、内存重用,这些设置可以在Profile.cpp里找到。
void Profile::setBasicProfile()
{
setUseCVSRAMAllocate(false);
setUseMemPool(false);
setUseReusePooledMemory(false);
setUseGreedyEviction(false);
setCanSDPBustNOPs(false);
setCanSDPMergeMathOps(false);
setCanSDPFuseSubEngineOps(false);
}最常使用的,也是官方给的默认参数-fast-math指令编译的配置如下:
void Profile::setFastMathProfile()
{
setPerformanceProfile();
setCanSDPMergeMathOps(true);
setCanSDPFuseSubEngineOps(true);
}在aarch64的模拟器里运行runtime、fast-math和default的速度差异是非常明显的,
为什么要指定int8模式?
因为nvsmall的配置是不支持16位运算的,此外,有关NVDLA的INT8量化,可以看这篇post。
关于Compiler还做了哪些事情,我们在以后的文章里讨论,这里我们只需要关心的是Compiler最后生成的目标文件,即Loadable。
在sw的仓库里,我们可以找到loadable.fbs文件,说明loadable是使用FlatBuffers做位压缩手段,这将是这篇博客的开始。
1. FlatBuffers 简介
FlatBuffers是一个开源的、跨平台的、高效的、提供了C++/Java接口的序列化工具库。它是Google专门为游戏开发或其他性能敏感的应用程序需求而创建。尤其更适用于移动平台,这些平台上内存大小及带宽相比桌面系统都是受限的,而应用程序比如游戏又有更高的性能要求。它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而不需要任何解析开销。
简单来讲,我们需要在流中传输一个对象,比如网络流。一般我们需要把这个对象序列化之后才能在流中传输(例如,可以把对象直接转化为字符串),然后在接收端进行反序列化(例如把字符串解析成对象)。但是显然把对象转成字符串传输的方法效率十分低下,于是有了各种流的转换协议,FlatBuffers也是其中一种。
本文不具体讨论其是如何压缩对象,具体可以参照官方的文档。这里借用简书中的一个例子:
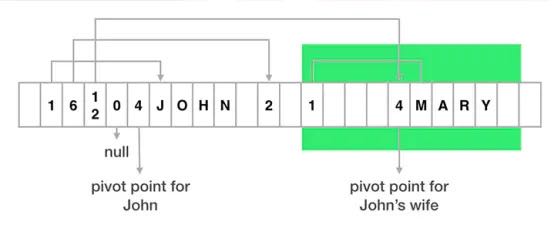
- 每一个存储在FlatBuffer中的对象,被分割成2部分:中心点(Pivot Point)左边的元数据(vtable)和中心点右边的真实数据。
- 每个字段都对应vtable中的一个槽(slot),它存储了那个字段的真实数据的偏移量。例如,John的vtable的第一个槽的值是1,表明John的名字被存储在John的中心点右边的一个字节的位置上。
- 如果一个字段是一个对象,那么它在vtable中的偏移量会指向子对象的中心点。比如,John的vtable中第三个槽指向Mary的中心点。
- 要表明某个字段现在没有数据,可以在vtable对应的槽中使用偏移量0来标注。
loadable.fbs由Schema语言组织,我们不需要添加定义,只需要考虑理解和读取。
1.1x 安装FlatBuffers
git clone https://github.com/google/flatbuffers.git
git checkout v1.6.0
cmake -G "Unix Makefiles"
make
make install 确认是否安装成功:
promote at ~/flatbuffers ±(cebdad4d) ✗ ❯ flatc --version
flatc version 1.6.0 (Mar 30 2021)在笔者写这篇博客的时候,flatc的版本已经是v1.12.0了,在官方仓库里的flatbuffers.h文件里可以发现,其使用的flatbuffers的版本是1.6.0:
#define FLATBUFFERS_VERSION_MAJOR 1
#define FLATBUFFERS_VERSION_MINOR 6
#define FLATBUFFERS_VERSION_REVISION 0虽然flatterbuffers声称其有非常好的前后兼容性,但是v1.12.0的程式与官方的代码有些对不上号,为了方便起见,这里在安装的时候把版本回退到v1.6.0.
生成loadable_generated.h,在我们的项目里引入这个头文件就可以读取loadable了。
flatc -c loadable.fbsFlatBuffers是轻依赖的,生成的头文件也只需要依赖flatbuffers.h,在我的项目目录下,这样组织文件,flatbuffers文件夹直接拷贝flatbuffers/include目录下的flatbuffers文件夹,但其实只需要拷贝flatbuffers.h就可以:
promote at ~/nvdla-depicter/external ±(master) ✗ ❯ tree
.
├── flatbuffers
│ ├── code_generators.h
│ ├── flatbuffers.h
│ ├── flatc.h
│ ├── flexbuffers.h
│ ├── grpc.h
│ ├── hash.h
│ ├── idl.h
│ ├── reflection.h
│ ├── reflection_generated.h
│ └── util.h
├── half.h
├── loadable.fbs
└── loadable_generated.h2. 解析loadble
看examples/0.loadable.read.cpp文件,读取了loadable文件的root_type,然后打印出其各个成员的size,测试我们是否是真的读取了loadable。
本章节的2.1-2.19分别对应examples文件夹下的9个文件的输出,即loadable.fbs里定义的root的组织结构的具体内容:
table Loadable {
version : Version ( required );
task_list : [TaskListEntry];
memory_list : [MemoryListEntry];
address_list : [AddressListEntry];
event_list : [EventListEntry];
blobs : [Blob];
tensor_desc_list : [TensorDescListEntry];
reloc_list : [RelocListEntry];
submit_list : [SubmitListEntry];
}
root_type Loadable;version不明白是用来做什么的,这里代表的不是使用的flatbuffers的版本,估计是compiler开发的版本?。
task_list是任务列表,就两个任务,第一个是DLA、第二个是EMU,应该分别代表硬件加速核和仿真器,tasklisk的address_list代表了每个task访问地址的列表。
memory_list是内存列表,我们可以通过task_list->address_list拿到addres_list的index,然后通过address_list->memory_id找到读取哪一块内存。
address_list是地址列表
event_list在runtime里似乎没有用到
blobs是存储数据的地方,分析blob的每个字段都有name,对应了memory里的name。
tensor_desc_list定义了输入层和输出层的tensor描述。
reloc_list\submit_list也不知道干嘛的
2.1x version
Loadable Version is 0.7.02.2x task_list
Loadable TaskListEntry :
id : 0
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 1
instance : -1
address_list : 5 1 2 3 4 6 7 8 9 10
pre_actions :
post_actions List : 0
Loadable TaskListEntry :
id : 1
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 2
instance : -1
address_list : 11 1 2 3 4 12 13 14 15 16
pre_actions : 1
post_actions List : 2 2.3x memory_list
Loadable memory_list :
id : 0
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 1
size : 4096
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 1
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 925696
alignment : 4096
contents size 8 : tb-0 tb-2 tb-3 tb-4 tb-5 tb-6 tb-8 tb-9
offsets size 8 : 0 4096 32768 8192 524288 12288 16384 24576
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 2
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 1
size : 24576
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 3
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 5
size : 6272
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 4
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 9
size : 16
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 1
Loadable memory_list :
id : 5
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 40
alignment : 4096
contents size 1 : task-0-addr0
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 6
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 360
alignment : 4096
contents size 1 : task-0-dep_graph
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 7
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 1160
alignment : 4096
contents size 1 : task-0-op_list
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 8
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 6440
alignment : 4096
contents size 1 : task-0-surf_list
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 9
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 700
alignment : 4096
contents size 1 : task-0-lut_list
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 10
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 1
size : 4096
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 11
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 256
alignment : 4096
contents size 1 : task-1-addr0
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 12
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 24
alignment : 4096
contents size 1 : task-1-op_list
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 13
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 3
size : 512
alignment : 4096
contents size 1 : task-1-op_buf_list
offsets size 1 : 0
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 14
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 1
size : 4096
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 15
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 1
size : 4096
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 0
Loadable memory_list :
id : 16
domain { SYSTEM = 0, SRAM = 1 } : 0
flags { NONE = 0, ALLOC = 1, SET = 2, INPUT = 4, OUTPUT = 8 } : 1
size : 4096
alignment : 4096
contents size 0 :
offsets size 0 :
bind_id : 0
tensor_desc_id : 02.4x address_list
Loadable AddressListEntry :
id : 0
mem_id : 0
offset : 0
size : 4096
Loadable AddressListEntry :
id : 1
mem_id : 1
offset : 0
size : 925696
Loadable AddressListEntry :
id : 2
mem_id : 2
offset : 0
size : 24576
Loadable AddressListEntry :
id : 3
mem_id : 3
offset : 0
size : 6272
Loadable AddressListEntry :
id : 4
mem_id : 4
offset : 0
size : 16
Loadable AddressListEntry :
id : 5
mem_id : 5
offset : 0
size : 40
Loadable AddressListEntry :
id : 6
mem_id : 6
offset : 0
size : 360
Loadable AddressListEntry :
id : 7
mem_id : 7
offset : 0
size : 1160
Loadable AddressListEntry :
id : 8
mem_id : 8
offset : 0
size : 6440
Loadable AddressListEntry :
id : 9
mem_id : 9
offset : 0
size : 700
Loadable AddressListEntry :
id : 10
mem_id : 10
offset : 0
size : 4096
Loadable AddressListEntry :
id : 11
mem_id : 11
offset : 0
size : 256
Loadable AddressListEntry :
id : 12
mem_id : 12
offset : 0
size : 24
Loadable AddressListEntry :
id : 13
mem_id : 13
offset : 0
size : 512
Loadable AddressListEntry :
id : 14
mem_id : 14
offset : 0
size : 4096
Loadable AddressListEntry :
id : 15
mem_id : 15
offset : 0
size : 4096
Loadable AddressListEntry :
id : 16
mem_id : 16
offset : 0
size : 40962.5x event_list
Loadable event_list :
id : 0
type { EVENTTYPE0 = 0, EVENTTYPE1 = 1, EVENTTYPE2 = 2 } : 0
target : 0
val : 1
op { WAIT = 0, SIGNAL = 1 } : 1
Loadable event_list :
id : 1
type { EVENTTYPE0 = 0, EVENTTYPE1 = 1, EVENTTYPE2 = 2 } : 0
target : 0
val : 1
op { WAIT = 0, SIGNAL = 1 } : 0
Loadable event_list :
id : 2
type { EVENTTYPE0 = 0, EVENTTYPE1 = 1, EVENTTYPE2 = 2 } : 0
target : 0
val : 2
op { WAIT = 0, SIGNAL = 1 } : 12.6x blobs
Loadable Blob : 0
name : task-0-addr0
size : 40
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 1
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 1
version : 0.12.3
data size is 40 :
Loadable Blob : 1
name : task-0-dep_graph
size : 360
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 1
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 2
version : 0.12.3
data size is 360 :
Loadable Blob : 2
name : task-0-lut_list
size : 700
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 1
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 5
version : 0.12.3
data size is 700 :
Loadable Blob : 3
name : task-0-op_list
size : 1160
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 1
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 3
version : 0.12.3
data size is 1160 :
Loadable Blob : 4
name : task-0-surf_list
size : 6440
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 1
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 4
version : 0.12.3
data size is 6440 :
Loadable Blob : 5
name : task-1-addr0
size : 256
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 2
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 1
version : 0.0.1
data size is 256 :
Loadable Blob : 6
name : task-1-op_buf_list
size : 512
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 2
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 4
version : 0.0.1
data size is 512 :
Loadable Blob : 7
name : task-1-op_list
size : 24
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 2
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 3
version : 0.0.1
data size is 24 :
Loadable Blob : 8
name : tb-0
size : 504
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 504 :
Loadable Blob : 9
name : tb-2
size : 40
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 40 :
Loadable Blob : 10
name : tb-3
size : 25000
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 25000 :
Loadable Blob : 11
name : tb-4
size : 100
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 100 :
Loadable Blob : 12
name : tb-5
size : 400000
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 400000 :
Loadable Blob : 13
name : tb-6
size : 1000
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 1000 :
Loadable Blob : 14
name : tb-8
size : 5000
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 5000 :
Loadable Blob : 15
name : tb-9
size : 20
interface { NONE = 0, DLA1 = 1, EMU1 = 2 } : 0
sub_interface {0:NONE 1:ADDR0 2:DEPS 3:OPS 4:SURFS 5:LUTS} : 0
version : 0.0.0
data size is 20 : 2.7x tensor_desc_list
Loadable tensor_desc_list :
name : data
id : 0
size : 6272
offset : 0
data_format { UNKNOWN = 0, NCHW = 1, NHWC = 2 } : 3
data_type { UNKNOWN = 0, FLOAT = 1, HALF = 2, INT16 = 3, INT8 = 4 } : 4
data_category { IMAGE = 0, WEIGHT = 1, FEATURE = 2, PLANAR = 3, BIAS = 4 } : 2
pixel_format {
R8 = 0,
R10 = 1,
R12 = 2,
R16 = 3,
R16_I = 4,
R16_F = 5,
A16B16G16R16 = 6,
X16B16G16R16 = 7,
A16B16G16R16_F = 8,
A16Y16U16V16 = 9,
V16U16Y16A16 = 10,
A16Y16U16V16_F = 11,
A8B8G8R8 = 12,
A8R8G8B8 = 13,
B8G8R8A8 = 14,
R8G8B8A8 = 15,
X8B8G8R8 = 16,
X8R8G8B8 = 17,
B8G8R8X8 = 18,
R8G8B8X8 = 19,
A2B10G10R10 = 20,
A2R10G10B10 = 21,
B10G10R10A2 = 22,
R10G10B10A2 = 23,
A2Y10U10V10 = 24,
V10U10Y10A2 = 25,
A8Y8U8V8 = 26,
V8U8Y8A8 = 27,
Y8_U8V8_N444 = 28,
Y8_V8U8_N444 = 29,
Y10_U10V10_N444 = 30,
Y10_V10U10_N444 = 31,
Y12_U12V12_N444 = 32,
Y12_V12U12_N444 = 33,
Y16_U16V16_N444 = 34,
Y16_V16U16_N444 = 35,
FEATURE = 36
} : 37
pixel_mapping { PITCH_LINEAR = 0, INVALID_PIXEL_MAP = 1 } : 0
n : 1
c : 1
w : 28
h : 28
stride_0 : 1
stride_1 : 224
stride_2 : 6272
stride_3 : 0
stride_4 : 0
stride_5 : 0
stride_6 : 0
stride_7 : 0
Loadable tensor_desc_list :
name : prob
id : 1
size : 16
offset : 0
data_format { UNKNOWN = 0, NCHW = 1, NHWC = 2 } : 3
data_type { UNKNOWN = 0, FLOAT = 1, HALF = 2, INT16 = 3, INT8 = 4 } : 4
data_category { IMAGE = 0, WEIGHT = 1, FEATURE = 2, PLANAR = 3, BIAS = 4 } : 2
pixel_format {
R8 = 0,
R10 = 1,
R12 = 2,
R16 = 3,
R16_I = 4,
R16_F = 5,
A16B16G16R16 = 6,
X16B16G16R16 = 7,
A16B16G16R16_F = 8,
A16Y16U16V16 = 9,
V16U16Y16A16 = 10,
A16Y16U16V16_F = 11,
A8B8G8R8 = 12,
A8R8G8B8 = 13,
B8G8R8A8 = 14,
R8G8B8A8 = 15,
X8B8G8R8 = 16,
X8R8G8B8 = 17,
B8G8R8X8 = 18,
R8G8B8X8 = 19,
A2B10G10R10 = 20,
A2R10G10B10 = 21,
B10G10R10A2 = 22,
R10G10B10A2 = 23,
A2Y10U10V10 = 24,
V10U10Y10A2 = 25,
A8Y8U8V8 = 26,
V8U8Y8A8 = 27,
Y8_U8V8_N444 = 28,
Y8_V8U8_N444 = 29,
Y10_U10V10_N444 = 30,
Y10_V10U10_N444 = 31,
Y12_U12V12_N444 = 32,
Y12_V12U12_N444 = 33,
Y16_U16V16_N444 = 34,
Y16_V16U16_N444 = 35,
FEATURE = 36
} : 37
pixel_mapping { PITCH_LINEAR = 0, INVALID_PIXEL_MAP = 1 } : 0
n : 1
c : 10
w : 1
h : 1
stride_0 : 1
stride_1 : 8
stride_2 : 8
stride_3 : 0
stride_4 : 0
stride_5 : 0
stride_6 : 0
stride_7 : 02.8x reloc_list
Loadable reloc_list :
address_id : 3
write_id : 8
offset : 116
interface : 1
sub_interface : 4
reloc_type : 1
Loadable reloc_list :
address_id : 3
write_id : 8
offset : 120
interface : 1
sub_interface : 4
reloc_type : 2
Loadable reloc_list :
address_id : 4
write_id : 13
offset : 274
interface : 2
sub_interface : 4
reloc_type : 1
Loadable reloc_list :
address_id : 4
write_id : 13
offset : 278
interface : 2
sub_interface : 4
reloc_type : 22.9x submit_list
Loadable submit_list :
id : 0
task_id size is 1 :
0
Loadable submit_list :
id : 1
task_id size is 1 :
1 3 读取blobs里的数据
3.1x 读取网络描述信息
演示一下如何读取网络的定义,首先拿到task访问的第一个地址,再根据这个地址拿到name。
auto address_idx = TaskListEntry->address_list()->Get(0);
std::cout << address_idx << " : ";
auto memory_idx = root_address_list->Get(address_idx)->mem_id();
std::string contents_name;
if(root_memory_list->Get(memory_idx)->contents()->size())
contents_name = root_memory_list->Get(memory_idx)->contents()->Get(0)->c_str();通过比对name,得到blob_index,拿到对应的blob数据。
int blob_idx = 0;
for (auto b : *blobs){
if(!strcmp(b->name()->c_str(), contents_name.c_str())) break;
blob_idx++;
}
std::cout << "Blob index : " << blob_idx << std::endl;
auto blob = blobs->Get(blob_idx);接着,我从kmd的仓库里把dla_interface.h文件拷贝了过来,之前不懂为什么nvdla在定义这些结构体的时候它都要对齐,想来都是为这个准备的。
/**
* Network descriptor
*
* Contains all information to execute a network
*
* @op_head: Index of first operation of each type in operations list
* @num_rois: Number of ROIs
* @num_operations: Number of operations in one list
* @num_luts: Number of LUTs
*/
struct dla_network_desc {
int16_t operation_desc_index;
int16_t surface_desc_index;
int16_t dependency_graph_index;
int16_t lut_data_index;
int16_t roi_array_index;
int16_t surface_index;
int16_t stat_list_index;
int16_t reserved1;
int16_t op_head[DLA_OP_NUM];
uint16_t num_rois;
uint16_t num_operations;
uint16_t num_luts;
uint16_t num_addresses;
int16_t input_layer;
uint8_t dynamic_roi;
uint8_t reserved0;
} __attribute__((packed, aligned(4)));然后直接把blob的指针强制转化:
struct dla_network_desc * net_desc = (struct dla_network_desc *) blob->data()->data();读取出来数据,经过验证数据都是正确的。

* desc_index代表的数据是task访问内存的下标,我们可以根据这些数据一次访问到其他所有的结构体。
3.2x 封装Parser
最后,封装了一个Parser对象,直接给loadable对象即可把几个关键的结构体都读取出来:
using namespace std;
int main(int argc, char * argv[]) {
Test_app_args test_app_args = Test_app_args();
//Load loadable file.
auto loadable = get_loadable(test_app_args.inputName);
if(!loadable) {
printf("Error! Cannot open loadable file.\n");
return 0;
}
Parser lenet_mnist_parser(loadable);
return 0;
}Debug信息:
lenet_mnist_parser = {Parser}
network_desc = {dla_network_desc * | 0x7fe1e9760178} 0x7fe1e9760178
common_op_desc = {dla_common_op_desc * | 0x7fe1e975ffc4} 0x7fe1e975ffc4
surface_desc = {dla_surface_container * | 0x7fe1e975de94} 0x7fe1e975de94
bdma_surface = {dla_bdma_surface_desc}
conv_surface = {dla_conv_surface_desc}
weight_data = {dla_data_cube}
type = {uint16_t} 0
address = {int16_t} 1
offset = {uint32_t} 0
size = {uint32_t} 504
width = {uint16_t} 5
height = {uint16_t} 5
channel = {uint16_t} 1
reserved0 = {uint16_t} 0
line_stride = {uint32_t} 0
surf_stride = {uint32_t} 0
plane_stride = {uint32_t} 0
wmb_data = {dla_data_cube}
wgs_data = {dla_data_cube}
src_data = {dla_data_cube}
dst_data = {dla_data_cube}
offset_u = {int64_t} 0
in_line_uv_stride = {uint32_t} 0
sdp_surface = {dla_sdp_surface_desc}
pdp_surface = {dla_pdp_surface_desc}
cdp_surface = {dla_cdp_surface_desc}
rubik_surface = {dla_rubik_surface_desc}
operation_desc = {dla_operation_container * | 0x7fe1e975f804} 0x7fe1e975f804
loadable = {const nvdla::loadable::Loadable * | 0x7fe1e96f4034} 0x7fe1e96f4034
address_list = {Addr_list}
memory_list = {Mem_list}
Comments