近期在基于TVM(其实是bitblas.tl) 复现PPoPP 2023的一篇论文Stream-K: Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU . 简单来说,这个方法可以把k轴均匀地切分到每个SM上,从而缓解小shape下的SM Waves浪费(BitBLAS在Contiguous Batching等场景上确实碰到了这样的问题,为了优化这部分性能不得已去复现这个论文的方法。然而这篇Blog不讲Stream-K的算法与实现细节,也不讲BitBLAS, 而是来分析一下TVM的MergeSharedMemoryAllocations这一个Pass,原因是高效的Stream-K实现需要引入大量的shared memory,而TVM中负责进行Liveness分析来合并shared memory访存的这个Pass,在复杂场景下存在BUG,导致shared memory的复用达不到预期,阻止了我们探索更大的tile size. 为此不得不对这个Pass进行一下改进,本文记录一下对这个Pass的分析和修改,以及我相信大部分TVM的用户在Hack TVM的代码的时候都会头秃,穿插一些TVM的设计和调试经验)
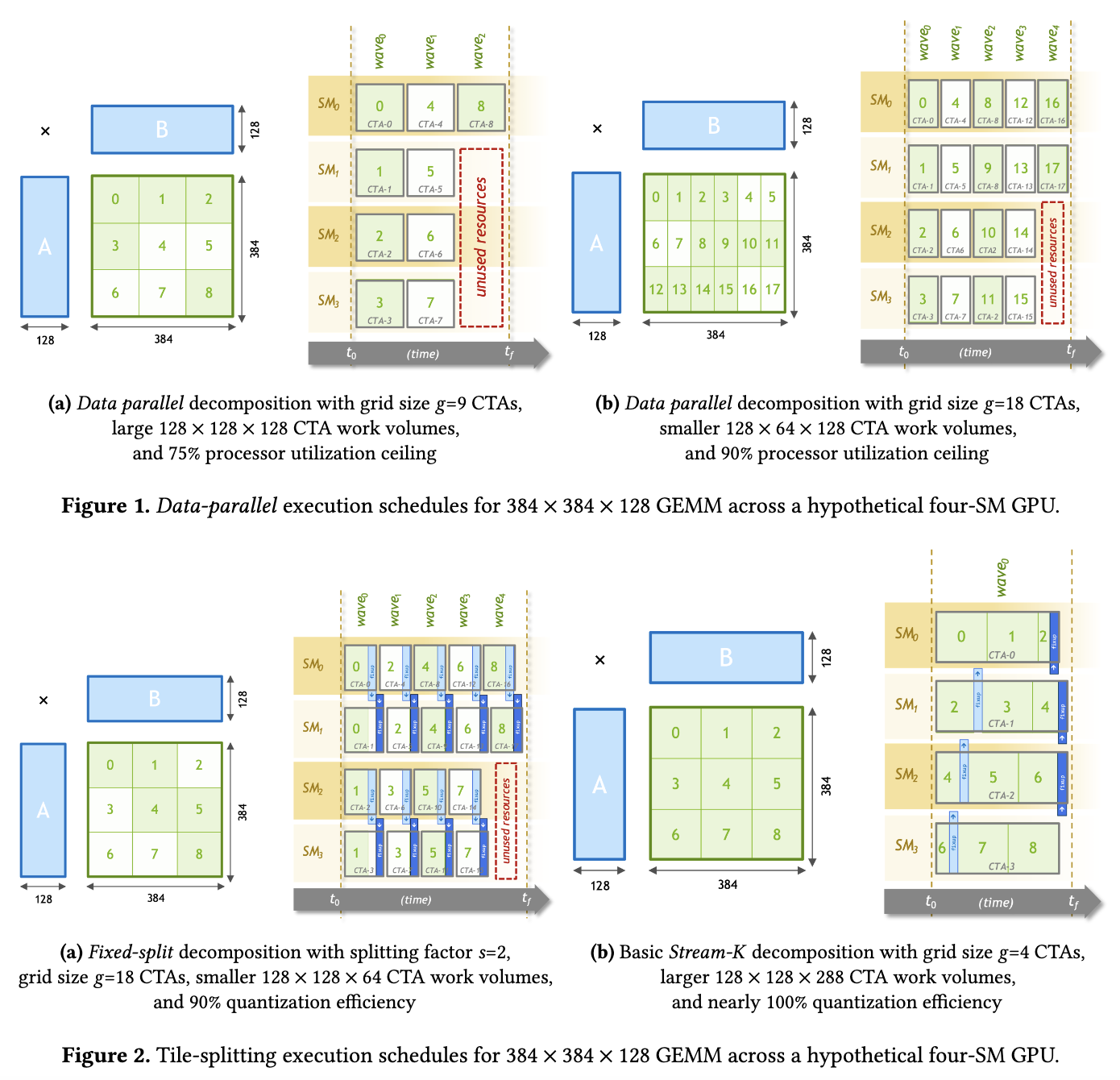
为什么需要 MergeSharedMemoryAllocations 这个 Pass
在高性能的GPU Kernel中,共享内存(shared memory) 的使用对于性能优化至关重要,普通的Tile划分需要在Shared Memory上做Cache,软件流水还会成倍得增加Shared Memory的使用,Block内跨线程Reduce等操作也需要通过Shared Memory作为媒介。以CUTLASS为例,不难发现高性能的Kernel都有着不低的Stage(及软件流水的层数,一般为3,或者4),这同样代表着高性能的Kernel需要使用不小的Shared Memory空间。试想一下,用户仿照CUTLASS的Tile Size手写一个高性能的Kernel,但是因为没有做Shared Memory的Reuse,导致使用的Shared Memory比CUTLASS多出一半,往往就会导致编译失败,丧失了一些优化机会。
而显然,我们可以使用一些静态分析的方法,例如Liveness Analysis,来分析出每个Buffer的生命周期,从而求解出一个Shared Memory Reuse的方案,而在TVM中,实现这一方案的Pass就是MergeSharedMemoryAllocations, 其主要功能是合并多次使用但生命周期不重叠的共享内存块。通过这样的合并操作,MLC(Machine Learning Compiler)可以减小存储器的碎片化,提升计算的性能和资源利用率。
考虑一个简单的矩阵乘法(Matrix-Matrix Multiplication, GEMM)场景,在这种场景下我们需要把输入矩阵和部分结果临时存储在共享内存中以加快计算速度。假设我们要计算矩阵 C = A * B,其中矩阵 A 的维度为 MxK,矩阵 B 的维度为 KxN。
在传统的Tile分块矩阵乘法(Block Matrix Multiplication)算法中,我们通常会将矩阵 A 和 B 切分成多个小块(Tile),并将这些块加载到共享内存中进行计算。这样做的好处是可以充分利用共享内存的高带宽和低延迟,减少对全局内存的访问次数,例如,在如下的代码片段中:
1 | |
这里的 Asub ,Bsub 和Csub是三个大小为 32x32 的共享内存块,一共会使用3072个float大小的shared memory,不难发现,当程序执行到Csub[threadIdx.y][threadIdx.x] = Cvalue;的时候,Asub和Bsub其实已经不会被使用到了,此时我们应该复用这部分存储,倘若如此,我们可以省下1024个float大小的shared memroy,相应的,我们可以探索更大的Tile Size或者Pipeline。而在常用的Tile Shape中,往往是BM~=BN >> BK的,这就导致C_shared往往很大,不复用存储会为硬件带来非常大的压力。
MergeSharedMemoryAllocations 的分析和改进
首先,我们需要简要回顾一下这个Pass的修改历史,社区的大佬masahi在2021年的时候写了最原始的Pass,[CUDA] Support multiple TIR-level dynamic shared memory allocations by masahi · Pull Request #8571 · apache/tvm (github.com) ,当时还没有活跃变量分析的内容,猜想只是因为dynamic shared memory只能声明一次,所以必须要把原本的多个alloc给整合成一个,年底的时候jinhongyii 在这个Pass上增加了对各个Buffer的活跃变量分析,使得Buffer可以被复用,再这之后的一些更改大部分是打打补丁(例如针对一些TVM的buildin intrin,例如异步拷贝和TensorCore相关的指令),去年的时候,我对这个Pass做了一个简单的改进,提高了一些场景下的复用率,并且将这个内容扩展到静态Shared Memory中去[CUDA] Simple extend to optimize reuse for static shared memory. by LeiWang1999 · Pull Request #16342 · apache/tvm (github.com),与此同时,这个Pass的名字也从MergeDynamicSharedMemoryAllocations变成了MergeSharedMemoryAllocations.(至于为什么不all in dynamic shared memory呢?其实作者当时是被ThreadSync这个Pass给坑了,在dynamic的时候莫名其妙多插了很多sync,导致笔者认为static在某些case下要更快,如今看来,这两者别无二致)。
讲过历史,我们来分析一下这个Pass的执行过程,代码的主体在merge_shared_memory_allocations.cc — LeiWang1999/tvm — GitHub. 如图所示,最主要的Class是SharedMemoryRewriter,主要的流程氛围三部,第一步是使用Visitor SharedMemLinearAccessPatternFinder来获得一个Buffer的LinearAccessPattern,他会返回一个作用域条目,这个条目有助于我们直接进行Livness分析(生成每个buffer的gen和kill point),最后Pass会根据Liveness分析的结果算出内存池的大小,和每个buffer的偏置,并改写语法树中对应Buffer的访问节点。
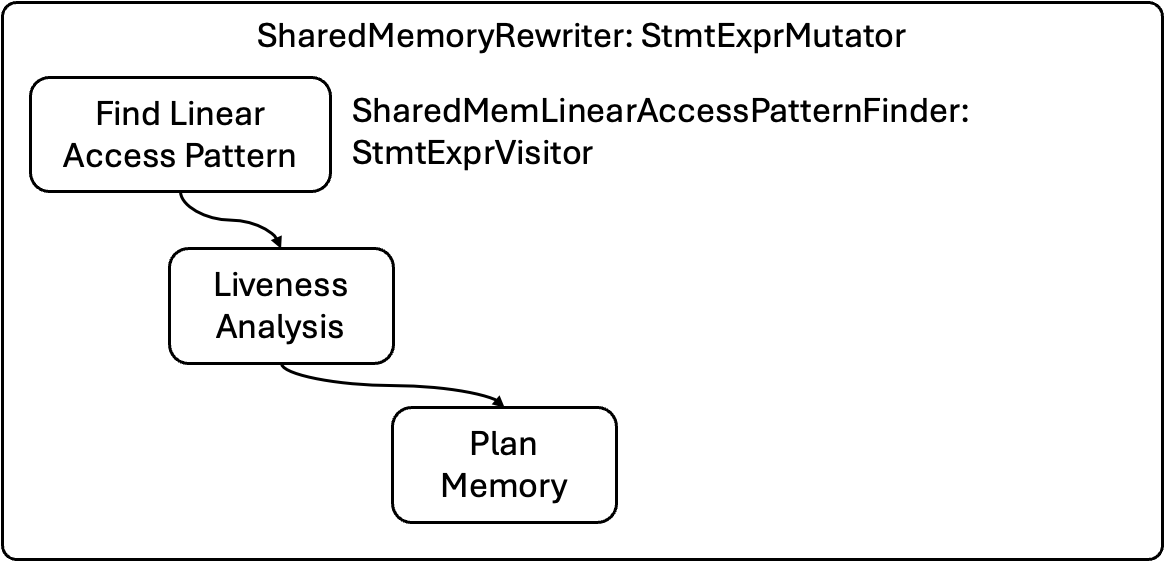
TVM Tips: StmtExprVisitor这个类可以被用来遍历TVM IR的语法树,一般用来从AST上统计一些信息,例如此处的作LinearAcessPattern,而StmtExprMutator则被用来修改AST上的节点。
先分析SharedMemLinearAccessPatternFinder这个Visitor,该类有两个关键的数据结构:
1 | |
在TVM中,,名字在Entry的数据结构是非常常见的,在数据结构设计中,Entry通常用来表示一个特定的数据条目或记录,在此处,它用于记录和管理共享内存的分配和使用信息,以支持后续的优化过程。通过这些条目,后续的Pass能够更好地理解程序的内存使用模式,从而进行生命周期分析。
SharedMemLinearAccessPatternFinder首先生成出AllocEntry,记录的是buffer的alloc节点处于内存的第几个level,其余的主要功能是记录每个作用域的开始和结束,形成一对作用域条目(scope entry):
- 当进入一个新作用域(如 For 循环或 IfThenElse 条件分支)时,它会将一个
StmtEntry条目推入linear_seq_,表示该作用域的开始,并在作用域结束时再插入一个条目表示结束。 - 这种结构记录了每个共享内存分配语句和使用语句的嵌套关系,使后续的存活性分析能够准确地找出每个内存块的生存周期
那么,level代表的是什么意思呢?假设有以下代码片段,包含了多层嵌套的作用域:
1 | |
在这个例子中,作用域层次如下:
• Allocate(A, shared):位于最外层,level 为 0。
• Allocate(B, shared):位于 for 循环内部,level 为 1。
• Allocate(C, shared) 和 Allocate(D, shared):位于 if-else 分支内部,level 为 2。
在TVM的语法树设计中,最外层一般是AttrStmt,用来记录thread binding等信息,而Shared Memory只能在CUDA Kernel的最外层来Alloc,所以AllocEntry的Level一般都是在Level 1.
以一个调度完的矩阵乘法(此处以我实际使用的Stream-K为例子)进入该Pass之前(已经经过了SplitHostDevice, StorageRewrite等各种Pass)为例子:
1 | |
我们打印出统计出来的 Alloc Entry,其也是符合预期的。
1 | |
AllocEntry将帮助我们构建StmtEntry,在讲解如何构建StmtEntry之前,我们先来观察一下这个数据结构的成员:
- stmt, 记录该条目的语句的指针(例如ForNode, IF等,TVM的语句和表达式都派生自Object).
- scope_pair_offset: 记录这个语句在所有条目中的偏置,如果是大于0的,表示现在这个是该语句的开头(比如For循环的开头),如果是小于0的,则表示结尾(比如For循环的结尾)。
- touched:记录这个语句在代码上下文中访问(读或写)到的共享内存缓冲区变量。
TVM Tips: 如何可视化stmt(及一个const Object 指针)?
在 TVM 的 TIR 中,所有的语句(Stmt)和表达式(PrimExpr)都是由对象(Object)派生而来的。我们可以使用Object的GetTypeKey()方法获得这个Object到底是个什么内容,如果确定是语句,可以使用GetRef的方法获得这个语句,并且通过TVM的IR Printer打印出这个语句。
2
3
4if (entry.stmt) {
LOG(INFO) << "stmt type: " << entry.stmt->GetTypeKey();
LOG(INFO) << "stmt: " << GetRef<Stmt>(static_cast<const StmtNode*>(entry.stmt));
}
scope_pair_offset(下文简称offset), 是SharedMemLinearAccessPatternFinder 类中的一个关键概念,它表示语句条目(StmtEntry)在线性访问模式中的作用域配对偏移量。这个偏移量用于表示某个语句条目相对于其作用域(scope)开始或结束的距离,帮助我们理解和分析语句的嵌套结构。
同样的,从一个简单的例子出发:
1 | |
假设我们使用 SharedMemLinearAccessPatternFinder 来分析这个代码片段的共享内存访问模式。我们会得到如下的线性化序列(linear_seq_):
1 | |
通过 scope_pair_offset 值,编译器能够理解每个语句的作用域边界和嵌套结构:
- 找到作用域的开始和结束:通过正值
offset,我们知道从某个条目开始进入一个作用域;通过负值offset,我们知道到达了一个作用域的结束。 - 分析作用域的嵌套结构:根据偏移值,可以理解语句之间的嵌套关系,明确每个语句属于哪个作用域,这对于存活性分析和内存重用的规划非常重要。
同样,以刚刚的矩阵乘法为例子,我们打印出StmtEntry的内容。
1 | |
拿到了StmtEntry,就可以Buffer的生命周期分析了,此处的代码也非常之简介和明了, 通过统计buffer最先被touch的地方和最后被touch的地方,从而得到buffer的gen和kill Node.
1 | |
最后,通过PlanMemory来改变Buffer的访存,然而在这之前,我们首先需要根据生命周期分析的结果生成一个合并方案,这里又有三个辅助数据结构:存储空闲的内存块列表(const_free_map_ 和 sym_free_list_),以及分配信息映射(alloc_map_),遍历每个语句条目,分析其中的内存访问和释放操作,当碰到 kill 事件的时候释放不再需要的内存块,当碰到gen 事件的时候分配新的内存块或重用已释放的内存块。
kill 处理的代码解读:
1 | |
- 遍历每个
StmtEntry条目,检查event_map_(事件映射表)中是否存在与该条目相关的kill事件。 kill事件表示某些内存变量在当前作用域结束时已经不再需要。对于这些变量,调用Free方法将其从当前使用的内存中移除,并将其标记为可重用状态(放入空闲列表const_free_map_或sym_free_list_中)。
gen 处理的代码解读:
1 | |
- 遍历每个
StmtEntry条目,检查event_map_中是否存在与该条目相关的gen事件。 gen事件表示某些内存变量在当前作用域开始时需要被分配。- 对于这些变量:
- 使用
FindAlloc方法查找一个合适的内存块进行分配。如果当前没有可重用的内存块,则会分配新的内存块。 - 更新
alloc_map_,将分配信息映射到相应的变量。
- 使用
PlanMemory 方法的核心是根据共享内存块的生存周期和作用域层次,决定哪些内存块可以被合并或重用。
1 | |
FindAlloc方法用于查找一个合适的存储条目(StorageEntry)来分配给当前变量。- 在内存重用过程中,如果找到合适的空闲内存块,则将该块分配给当前变量并更新其分配状态;否则,分配一个新的内存块。
alloc_map_用于记录每个变量的存储条目信息,确保内存分配的正确性。
我们可以通过分析StorageEntry来确定最终的shared memory的总存储大小。
1 | |
之后,再语法树的开始插入一个新的Allocate节点,并且跳过所有原本的Allocate节点,已经更新DeclBuffer节点。
1 | |
通过访问BufferLoad和BufferStore节点,更新成unifiy buffer的访存位置等,例如从B_shared[i, j] 变成 smem[i * B_stride[0] + j + offset]
1 | |
BUG的发现和改进
上述Pass在GEMM里可以获得不错的效果,但是一方面,复用效果达不到最好,另一方面,处理touched buffer的逻辑有一点问题。
第一个问题,复用效果达不到最好,这个是因为StorageRewrite这个Pass,会进行一个简单的Buffer复用,这个方法保证了一定的可读性,但是很呆,具体的讨论见我之前的PR,https://github.com/apache/tvm/pull/16342 .
1 | |
如此,会浪费一部分的存储,我引入了一个option,tir.merge_static_smem来关闭StorageRewrite的merge.
1 | |
但是为了保证StaticSharedMemory的可读性,这个option默认是关闭的。
第二个问题,结合我们之前的分析,我们知道Shared Memory的Alloc节点都是在Level 1的,而通过touched_buffer更新的代码:
1 | |
不难发现,其每次都会把touched buffer放到最外围的(除了AttrStmt)Entry上,这个对于矩阵乘法来说刚好是对的,但是细想来看,这个touched buffer其实应该放到最内层的Entry上,Liveness分析中的Gen和Kill Point才不会出错,为了验证这个猜想,我们可以使用一个简单的batched gemm为例子(batch维度不并行化),这样最外围的(除了AttrStmt)Entry就是一个完整的ForLoop,这样所有的touched buffer都会被放到这个Entry上,那么该Pass就完全不会复用任何Buffer(因为每个Buffer的Gen Point都在AttrStmt的开头,Kill Point在AttrStmt的结尾), 在Stream-K的实现中,这个场景是更加复杂的,其表达式为:
1 | |
所以该问题的解法本质上也很简单,就是把touched buffer的更新模式换一下,尽可能使用最内层的Entry而不是最外层的。
1 | |
总结
好久没有写blog了,一千个基于TVM的项目,就有一千个被爆改过的TVM。相信很多TVM的使用者和初学者对改动CPP的Pass望而却步,笔者觉得最主要的坑还是文档太少了(但是社区也正在施工),TVM的CPP代码非常之优美,常看常新😭,感谢chengyu一起分析和定位了一下Bug,我正在糊Stream-K的实现正在施工中:) LeiWang1999/Stream-k.tvm (github.com),以及欢迎大家关注我最近在写的项目microsoft/BitBLAS !
Comments