最近狠狠重构了一下tilelang的auto tuning, 本文介绍一下tilelang的自动调优部分当作一个小文档,以及顺道回顾一下本作者眼中的机器学习编译领域的自动调优发展。
tilelang jit
继上文 运行时CUDA源代码转Torch Function的若干方法 评论区收集到了一些比较新颖的方案,例如pybind的作者新提出的bind方法nanobind, triton里生成了一个cpp使用PyObj来获得一个python对象的成员,从而获得torch的指针和shape等信息,以及mlc-python项目中使用的cython解决办法,花了一段时间在tilelang的jit部分添加了各种execution backend的实现,目前jit的execution backend包括dlpack,cpp_extension,ctypes以及cython这四个,我实际实现下来,cython的runtime overhead最小,实现最方便(熟练了cython之后),这里总结一下给各位出主意的同学们交差,顺便介绍一下tilelang的jit.
CUDA CPP to Torch Executable
很久之前笔者碰到过一个还挺棘手的问题: 怎么优雅的在运行时阶段自动把一个tvm生成的CUDA C文件封装成一个Torch Function? 作者大概尝试过三种方法,各有利弊:
- PyBind Torch C++ Extension: 最常见的是通过torch基于pybind开发的cpp extension,也是大部分库对接torch的时候使用的方法,但是这种方法的编译时长太久,在runtime下(比如tilelang/bitblas)这种编译的overhead会让用户体验明显变差。
- DLPack: DLPack应该是最直接的方式了,先将 Torch 张量转换为 DLPack 格式,然后再将其转换成 TVM 所需的参数。DLPack 的优点是使用时几乎无感,不需要像 PyBind 那样等待数十秒的编译时间。但它也存在一个不足:由于频繁通过 ctypes 进行调用,额外的运行时开销在小 kernel 场景下甚至可能超过 kernel 本身的执行时间。
- 静态编译与指针传递: 最Hack的方法是将 CUDA 源码提前静态编译成库文件,然后在 Python 端直接传递指针进行调用。虽然这样可以省去运行时的编译时间,也是bitblas目前使用的方法,但是在cpp侧损失了张量信息,没有办法做高性能的张量属性check(如果把这些放到python侧来做,则又会引入新的overhead)。
本文接下来再详细分享一下这三种方法的利弊与笔者做出的一些尝试与改进,包括怎么尽可能的减少torch cpp extension的编译overhead,怎么分析dlpack的overhead等,希望能够帮助到之后踩坑的同学以及供大家讨论 :) 代码放在CPPTorchExecutable
Write High Performance Matrix Multiplication via TileLang
前段时间我们悄咪咪release了tilelang,tilelang设计了三种不同的编程语法,设计中将分成了初学者、开发者和写Kernel的专家这三个等级,我们对Level 1的使用者的定义是不清楚目标硬件架构的开发者(例如不知道GPU的cache一般需要用到tiling,把数据层层cache),这个时候用户编写的程序只是一个简单的计算表达式,不包含任何schedule相关的信息(这样就和tvm的设计理念一样了),这种方法理论上来讲对于不太kernel的人是最舒服的,但是因为很多现存未解决的问题:
1. 从调优的角度来看,从计算到具体的schedule的自动调优时间一般要花比较久的时间,虽然一些工作例如MSRA System Research的Roller,利用硬件感知的白盒搜索空间生成缓解了这一问题, 请看BitBLAS对Roller的复现[Tutorial](https://github.com/microsoft/BitBLAS/blob/main/tutorials/1.fast_and_efficient_codegen.ipynb), 但知道并使用这种方法的人的人也不是很多
1. 从Kernel的表达能力角度来看,目前一些主流的复杂的计算并不能够通过schedule描述出来,例如Flash Attention, 虽然理想上应该可以通过推导 matmul+softmax+matmul 简单计算表达式的一种算子融合版本得到,但是这个问题从写文章的时间点来看仍然很困难。
1. 从社区来看,Schedule的代码虽然看起来还是很优雅的(从写schedule和理解schedule的角度来看, 例如bitblas对于matmul dequantize的[schedule模版](https://github.com/microsoft/BitBLAS/blob/main/bitblas/gpu/matmul_mma_dequantize.py)我个人觉得还是写的很通用的),schedule的魅力在于其从一个最原始不包含任何调度信息的计算表达式,在确保正确性不受影响的情况下一步步变换到最终的高性能调度形式。但是schedule实在太难学习和理解了,即使是一个会写schedule表达式的开发者(这部分玩家已经很少了),想要看明白我写的各种schedule模版,继续扩展也是非常非常困难的。其次,很复杂的计算,例如Flash Attention, 其因为设计本身是要在shared memory上进行算子融合所以计算是无法表达的,其次,即使是要强行写出特别针对Flash attention的多算子fuse版本的schedule模版,schedule本身的代码量可能会比cuda还要长(最后,同样受限于社区,tvm的生态逐渐变得不如triton,一些新feature例如tma这些的支持会有点滞后)于是在搞bitblas的时候我就觉得这一套有点难受(, 于是觉得需要一个类似triton的东西,但是triton的限制也很大,例如不能显式声明内存,不能显式控制线程的行为等,这一点之后分享的时候再讨论讨论。总之目前bitblas的所有kernel实现都已经换成了Tile Lang,自己用起来非常舒服。
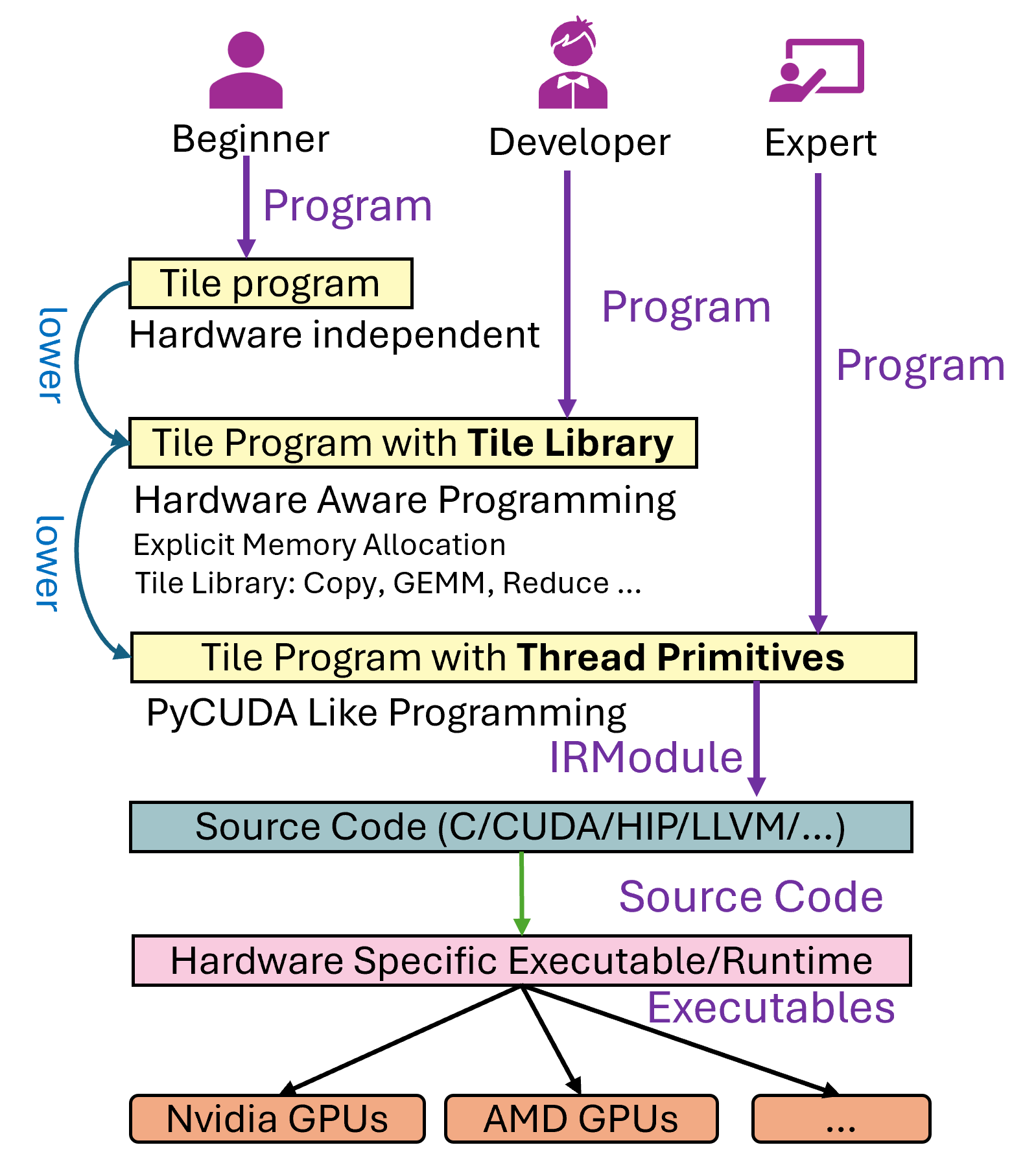
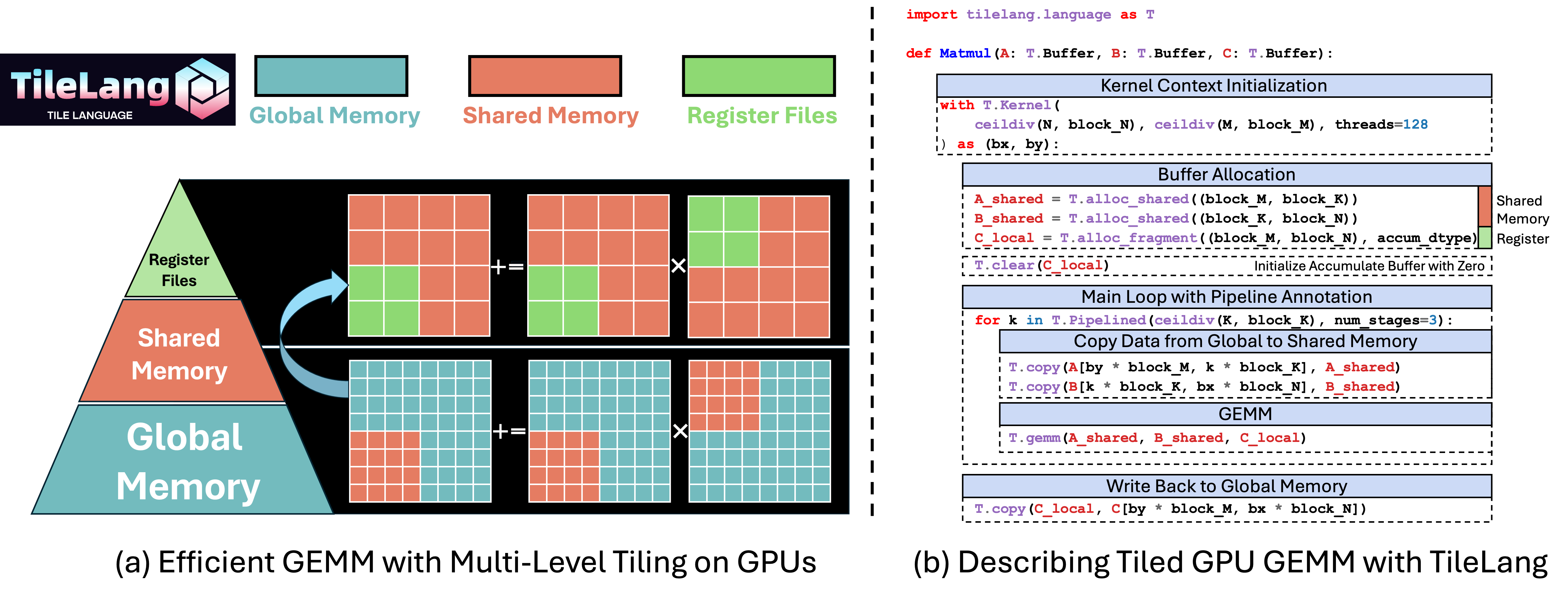
话说回来,我们对Level 2的使用者的定义是知道目标硬件架构的开发者,及在cuda上知道shared memory这个概念,知道在cuda上做tile要先把数据load到一个高速的缓存上再进行计算(有点类似triton的开发模式),本文我们以这种模式为例子介绍一下矩阵乘法Kernel的组成。
最后提一嘴Level 3, thread primitives允许用户完全控制每个线程的行为,写这一部分的代码其实就和写PyCUDA差不多了(但是支持多后端,例如HIP等),于是Level 3就是给完全的expert写的了,但本质上,经过LowerTileOP和LayoutInference这两个Pass之后,Level 2的代码也会被Lower到Level 3上。
所以非常值得一提的是,我们的设计中这三种语法可以出现在同一个program中,例如BitBLAS里的量化矩阵乘法的program中对于复杂的反量化部分,我们使用了thread primitives来精心控制每个线程的行为,以及利用ptx来加速精度转换的过程,显式在progam中调用mma 来在一些情况下在寄存器中做反量化等,其他的一些操作,例如数据拷贝和Pipeline仍然使用Level 2的编程方式(T.Pipelined, T.Copy)等,代码参考matmul_dequantize_tensorcore_finegrained.py。
Debug Tools for TileLang
翻译自: https://tilelang.tile-ai.cn/tutorials/debug_tools_for_tilelang.html
一个Tile Language程序(我们称为 program)到具体的硬件可执行文件的流程如下图所示,大致分为以下几步:1. 用户首先编写 Tile Language program。2. 程序会经过多个 Pass 的转换和优化处理(即 lower 阶段,相关代码位于 tilelang/engine/lower.py),最终生成中间代码,比如针对 CPU 的 LLVM 或 C 代码,或者针对 NVIDIA GPU 的 CUDA 代码等。3. 生成的中间代码会通过对应的编译器进一步编译,最终输出硬件可执行文件。
在这个过程中,用户可能会碰到大概三类问题:
1. Tile Language Program无法生成硬件可执行文件,也就是lower的过程中出现问题,我们可以归纳成生成问题。
1. 正确性问题,生成的可执行文件运行后,行为不符合预期。
1. 性能问题,执行文件的性能表现与硬件的理论值存在显著差距。本文将重点讨论前两类问题的调试方法。至于性能问题的调优,则需要结合硬件厂商提供的性能分析工具(如 Nsight Compute、rocProf 等),通过分析具体的硬件指标进一步优化,我们将在后续文章中详细探讨。
接下来,我们以矩阵乘法(Matrix Multiplication)为例,使用 Tile Language 展示如何编写和调试相关程序。
High Performance AMD Matrix Core Codegen
不久之前的一篇分享里,我介绍了AMD CDNA架构(MI210, MI250, MI300)上的异步拷贝相关指令,在BitBLAS可以找到相关的实现,然而实际过程中发现AMD的异步拷贝指令的要求实际上要比那篇分享所写的更加苛刻,每个warp里的线程必须要求访问连续的数据,或者通过M0寄存器来控制每个线程的偏置。
一般来说,我们习惯这个指令就是明确的要load给定指针的一小块数据就行了,但是这个指令因为上述提到的两个限制就很难做到。经过笔者非常繁琐的Micro bencmark之后,笔者终于调教出了可以让每个线程Load给定数据块的写法,如下:
1 | |
在这篇文章里,笔者填一下AMD Matrix Core的坑,介绍一下过去一个月里BitBLAS针对AMD的的高性能Matrix Core支持,在这篇文章里笔者将介绍一下MFMA(AMD版的MMA)。如何进行AMD Kernel的性能分析,及Profile一个AMD Kernel,最后我们介绍若干种绞尽了笔者脑汁的优化方法,完全利用好硬件的带宽(全都是128bits的内存访问指令,并且没有Memory bank conflict)。
这篇文章涉及到的算子有矩阵乘法和Flash Attention。本篇文章的实现在BitBLAS里, Codegen以及Swizzle等Layout变换依托于TVM, TVM可以帮助我们显式地操作一个数据的Layout,相比Triton更加灵活和可观。虽然AMD提供的文档十分有限,但是在这一个月里笔者参考了很多AMD开发人员提供的实现,例如Composable Kernel和Triton for ROCm,笔者从这些项目中收获良多。
本文假设读者对Nvidia GPU的编程有一定的了解,熟悉最基本的Tile优化程序的方法,以及Tensor Core的基本概念。