翻译自: https://tilelang.tile-ai.cn/tutorials/debug_tools_for_tilelang.html
一个Tile Language程序(我们称为 program)到具体的硬件可执行文件的流程如下图所示,大致分为以下几步:1. 用户首先编写 Tile Language program。2. 程序会经过多个 Pass 的转换和优化处理(即 lower 阶段,相关代码位于 tilelang/engine/lower.py),最终生成中间代码,比如针对 CPU 的 LLVM 或 C 代码,或者针对 NVIDIA GPU 的 CUDA 代码等。3. 生成的中间代码会通过对应的编译器进一步编译,最终输出硬件可执行文件。
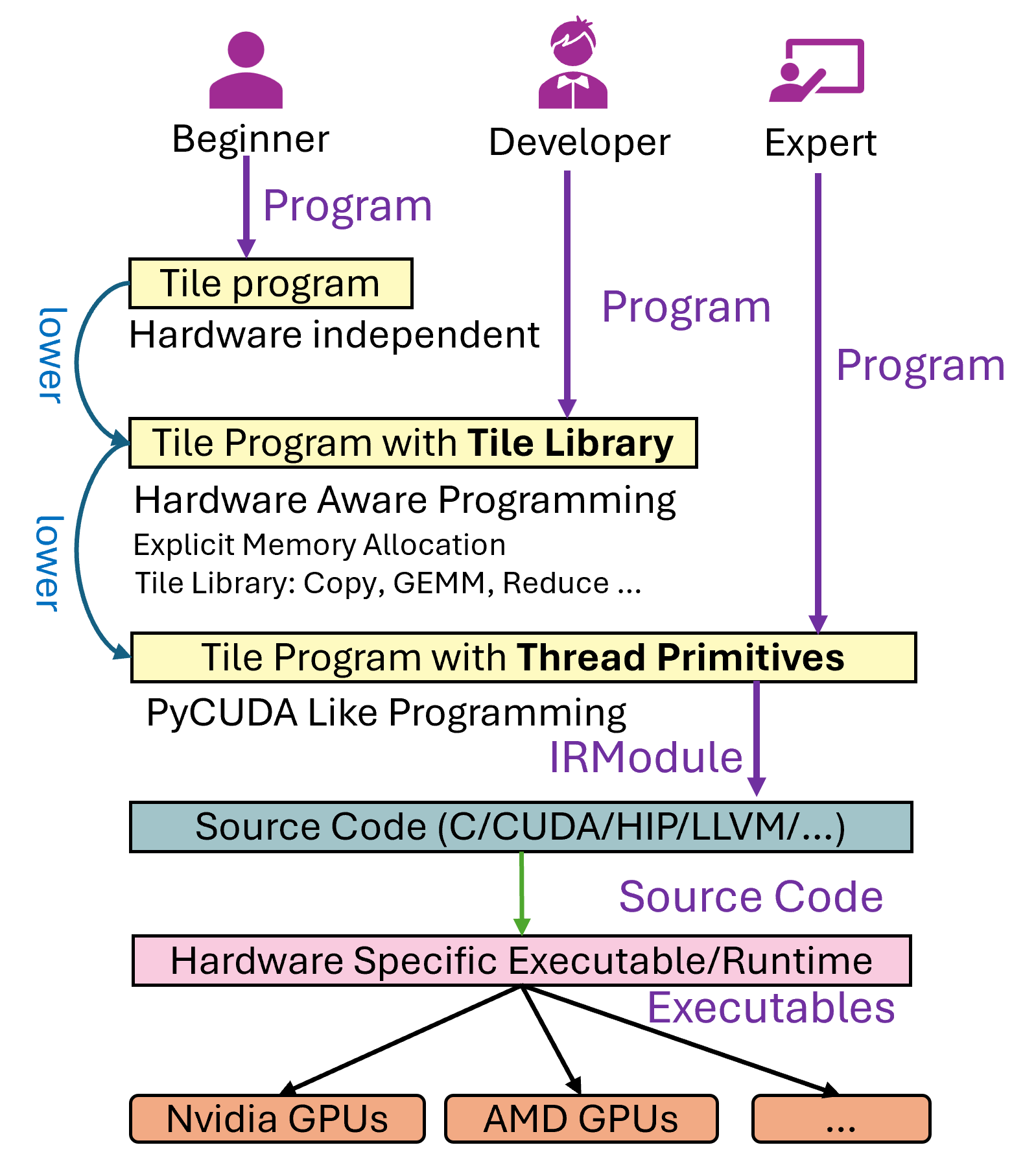
在这个过程中,用户可能会碰到大概三类问题:
1. Tile Language Program无法生成硬件可执行文件,也就是lower的过程中出现问题,我们可以归纳成生成问题。
1. 正确性问题,生成的可执行文件运行后,行为不符合预期。
1. 性能问题,执行文件的性能表现与硬件的理论值存在显著差距。本文将重点讨论前两类问题的调试方法。至于性能问题的调优,则需要结合硬件厂商提供的性能分析工具(如 Nsight Compute、rocProf 等),通过分析具体的硬件指标进一步优化,我们将在后续文章中详细探讨。
接下来,我们以矩阵乘法(Matrix Multiplication)为例,使用 Tile Language 展示如何编写和调试相关程序。