最近狠狠重构了一下tilelang的auto tuning, 本文介绍一下tilelang的自动调优部分当作一个小文档,以及顺道回顾一下本作者眼中的机器学习编译领域的自动调优发展。
tilelang jit
继上文 运行时CUDA源代码转Torch Function的若干方法 评论区收集到了一些比较新颖的方案,例如pybind的作者新提出的bind方法nanobind, triton里生成了一个cpp使用PyObj来获得一个python对象的成员,从而获得torch的指针和shape等信息,以及mlc-python项目中使用的cython解决办法,花了一段时间在tilelang的jit部分添加了各种execution backend的实现,目前jit的execution backend包括dlpack,cpp_extension,ctypes以及cython这四个,我实际实现下来,cython的runtime overhead最小,实现最方便(熟练了cython之后),这里总结一下给各位出主意的同学们交差,顺便介绍一下tilelang的jit.
CUDA CPP to Torch Executable
很久之前笔者碰到过一个还挺棘手的问题: 怎么优雅的在运行时阶段自动把一个tvm生成的CUDA C文件封装成一个Torch Function? 作者大概尝试过三种方法,各有利弊:
- PyBind Torch C++ Extension: 最常见的是通过torch基于pybind开发的cpp extension,也是大部分库对接torch的时候使用的方法,但是这种方法的编译时长太久,在runtime下(比如tilelang/bitblas)这种编译的overhead会让用户体验明显变差。
- DLPack: DLPack应该是最直接的方式了,先将 Torch 张量转换为 DLPack 格式,然后再将其转换成 TVM 所需的参数。DLPack 的优点是使用时几乎无感,不需要像 PyBind 那样等待数十秒的编译时间。但它也存在一个不足:由于频繁通过 ctypes 进行调用,额外的运行时开销在小 kernel 场景下甚至可能超过 kernel 本身的执行时间。
- 静态编译与指针传递: 最Hack的方法是将 CUDA 源码提前静态编译成库文件,然后在 Python 端直接传递指针进行调用。虽然这样可以省去运行时的编译时间,也是bitblas目前使用的方法,但是在cpp侧损失了张量信息,没有办法做高性能的张量属性check(如果把这些放到python侧来做,则又会引入新的overhead)。
本文接下来再详细分享一下这三种方法的利弊与笔者做出的一些尝试与改进,包括怎么尽可能的减少torch cpp extension的编译overhead,怎么分析dlpack的overhead等,希望能够帮助到之后踩坑的同学以及供大家讨论 :) 代码放在CPPTorchExecutable
TVM中的Shared Memory Reuse Pass 分析
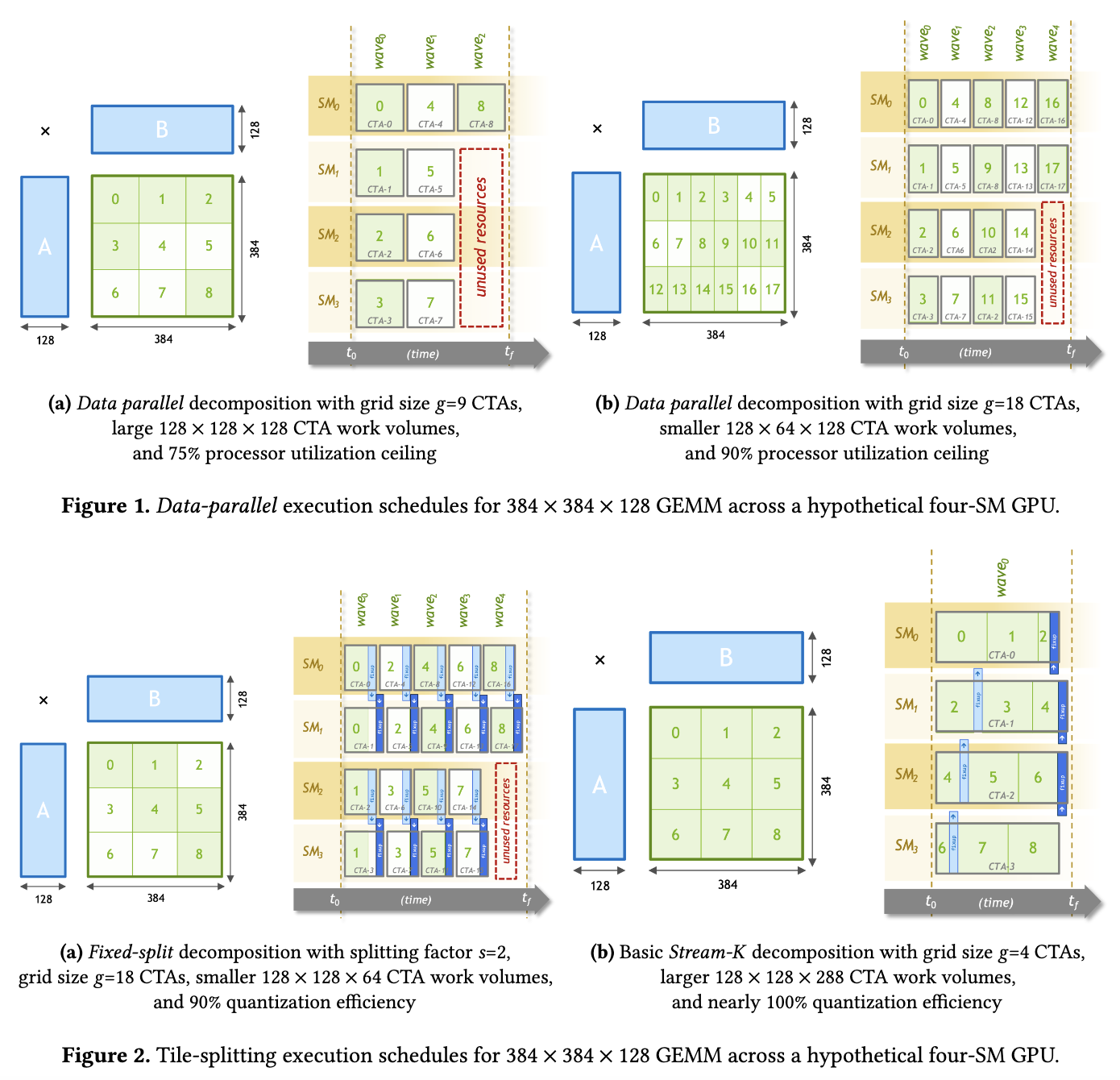
近期在基于TVM(其实是bitblas.tl) 复现PPoPP 2023的一篇论文Stream-K: Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU . 简单来说,这个方法可以把k轴均匀地切分到每个SM上,从而缓解小shape下的SM Waves浪费(BitBLAS在Contiguous Batching等场景上确实碰到了这样的问题,为了优化这部分性能不得已去复现这个论文的方法。然而这篇Blog不讲Stream-K的算法与实现细节,也不讲BitBLAS, 而是来分析一下TVM的MergeSharedMemoryAllocations这一个Pass,原因是高效的Stream-K实现需要引入大量的shared memory,而TVM中负责进行Liveness分析来合并shared memory访存的这个Pass,在复杂场景下存在BUG,导致shared memory的复用达不到预期,阻止了我们探索更大的tile size. 为此不得不对这个Pass进行一下改进,本文记录一下对这个Pass的分析和修改,以及我相信大部分TVM的用户在Hack TVM的代码的时候都会头秃,穿插一些TVM的设计和调试经验)
为什么padding能解bank conflict?
之前回答某个知乎问题的时候简单描述了一下为什么通过加padding的方式可以解bank conflict:
https://www.zhihu.com/question/565420155
当时我画了这样一个图片:
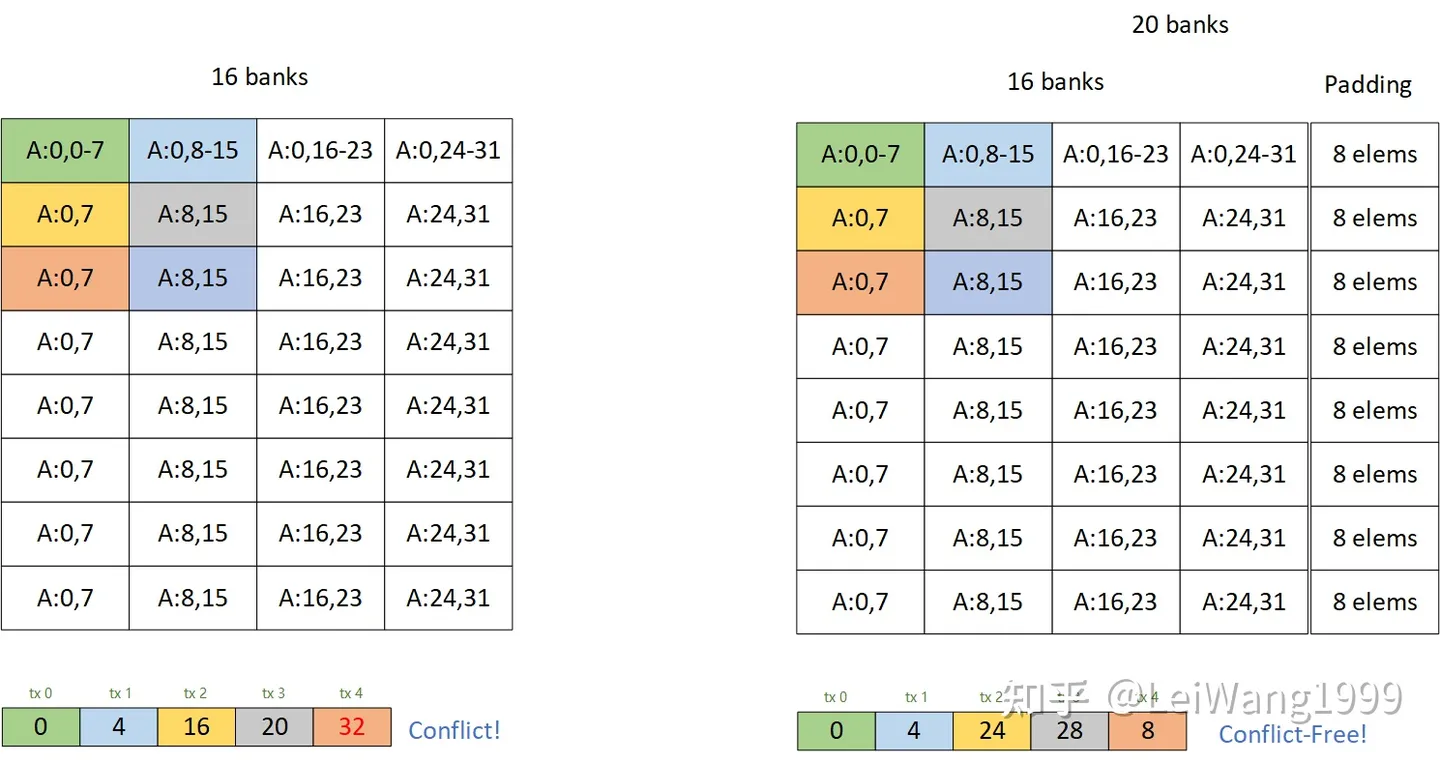
有一些同学还是不理解为什么这种方式可以解掉bank conflict,再加上我搜一搜也没发现有人讲清楚过这件事情。这篇文章以利用tensor core的矩阵乘法为例,较详细地分析一下解conflict的方法,同样我们选择一个最典型的cutlass tile 128x256x32 的 float16 的tile,用来说明问题,在最后,我会提供一份复现的代码,由Tensor IR实现,方便实现各种Tile(虽然我觉得加pad的性能并不能足够到sota。
tvm efficient gemm half2
在之前的两篇文章中,我们分别用TVM的Tensor Expression与TIR Script完成了在Nvidia Cuda Core上的高效的FP32 矩阵乘法,3090-24GB的各种精度在Cuda Core和Tensor Core上的Peak TFLOPS如下表所示:
| 3090-24GB | FP32 | FP16 | BF16 | INT32 | INT8 | INT4 |
|---|---|---|---|---|---|---|
| Cuda Core | 35.6 | 35.6 | 35.6 | 17.8 | 71.2 | \ |
| Tensor Core | \ | 142 / 284* | 142 / 284* | \ | 284 / 568* | 568 / 1136* |
有意思的是,3090上,FP16的Peak Peformance和FP32是一样的,这一点比较特殊,是因为架构上的改动,一般而言fp16的性能都会是fp32的两倍或者四倍,这个主要是因为20系的gpu把fp32和int32的Cuda Core分开了,从而能同时进行fp32和int32的计算,30系把int32的core又就加上了fp32的计算单元,所以fp32的计算能力翻倍,而cutlass下的16384的gemm。
按照3090上的硬件单元分类,我们还可以探索一些有意思的加速,比如在CUDA Core上使用SIMD指令(DP4A,HFMA2来优化int8、half的性能,