As discussed in Phasing out Legacy Components, Third-party developers often choose to directly apply inplace modification to TVM rather than contributing their changes upstream for several reasons. First, TVM’s codebase is complex, and understanding or modifying it requires significant effort. Developers frequently face scenarios where TVM’s existing capabilities cannot meet their specific optimization needs, such as adding custom schedules, transformation passes, or backends for certain hardware architectures. These custom modifications are often too specific or “hacky” to meet the high code quality and design standards required by the TVM community, making it difficult for such changes to be merged upstream. Furthermore, the process of contributing upstream can be cumbersome and time-consuming, requiring rigorous testing and CI checks, which may outweigh the benefits for individual projects. Additionally, developers often lock their forks to specific versions of TVM to stabilize their custom modifications, making it harder to keep up with upstream updates. As a result, it is easier and faster for developers to maintain their own fork rather than engage in the lengthy and complex process of merging code upstream. Finally, the diverse nature of TVM-based projects means that different forks often have highly specialized code, which is not always applicable to the broader community, further reducing the motivation to merge changes back into TVM’s mainline codebase.
通过Include依赖扩展TVM
之前在一篇文章中我提到过一句:一千个基于TVM的项目,就有一千个被爆改过的TVM,这是我对基于TVM开发项目现状的吐槽。理解TVM的代码对于开发者来说已经是一件不容易的事情,更不用说开发者们在面对一个当前TVM无法解决的场景,想要修改进行扩展的时候是怎样的困难。往往,基于TVM的项目都是Fork一份TVM的代码来修改,例如为TVM添加一个新的优化Pass,就在src/tir/transformation文件夹下面新建一个Pass文件,然后通过ffi绑定到python侧的代码,其他的需求,例如注册一个新的语法树节点,添加新的代码生成等,也都是如此来实现,我自己的github上fork的LeiWang1999/tvm就包含十几个分支,有为了BitBLAS扩展(引入了一些新的Node和Schedule来进行优化)的bitblas分支,有为了Ladder/Welder做高性能的算子融合而添加了一些优化Pass的ladder分支,有为给AMD上做代码生产的amd_hip分支。这些分支的关系已经非常错综复杂了,我以BitBLAS为例,探讨一下为什么这样的开发方式会导致困难,并且提供一种解决方法(参考自MLC-LLM),供大家一起讨论,代码放在LeiWang1999/TVM.CMakeExtend。
TVM中的Shared Memory Reuse Pass 分析
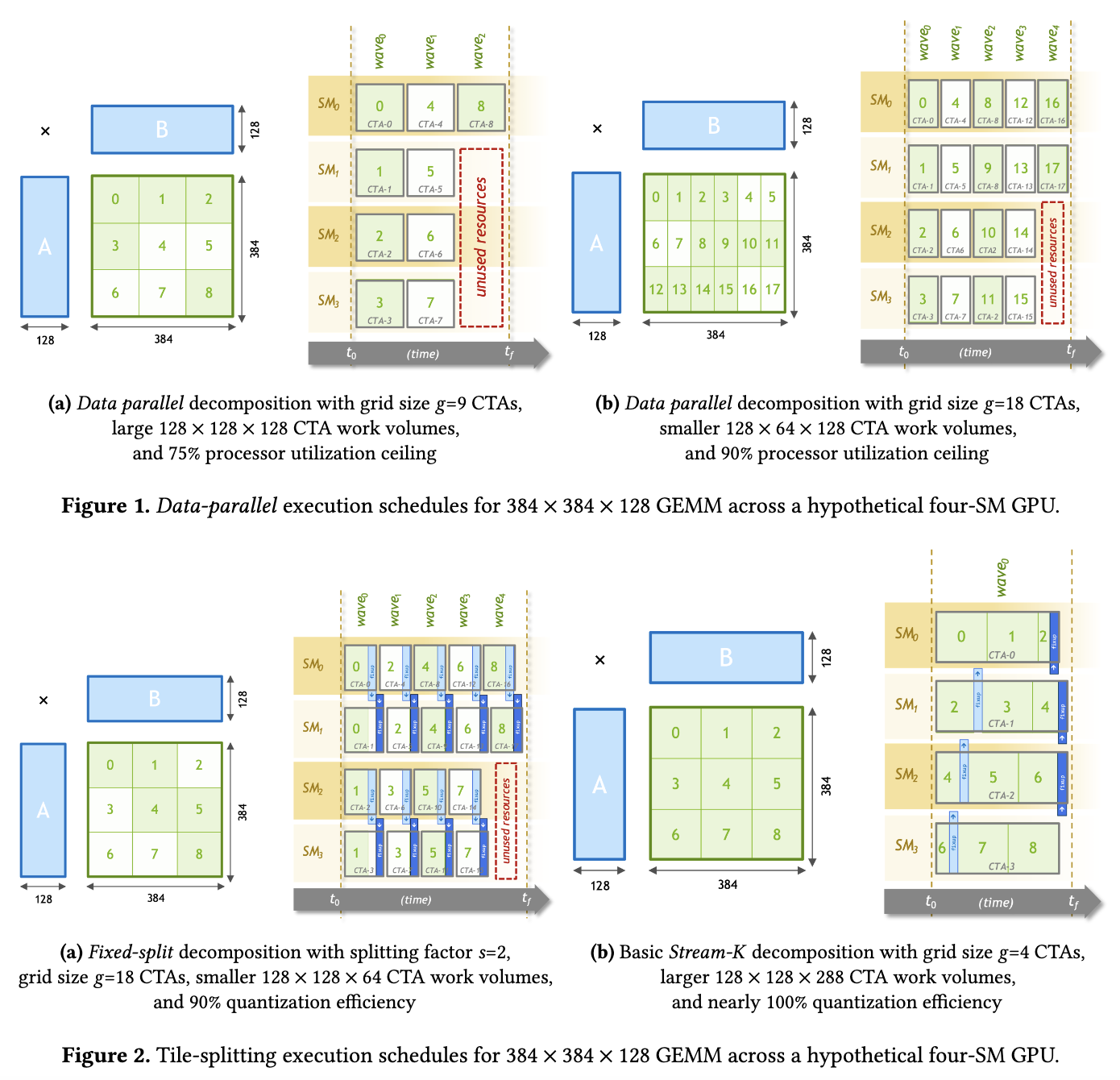
近期在基于TVM(其实是bitblas.tl) 复现PPoPP 2023的一篇论文Stream-K: Work-centric Parallel Decomposition for Dense Matrix-Matrix Multiplication on the GPU . 简单来说,这个方法可以把k轴均匀地切分到每个SM上,从而缓解小shape下的SM Waves浪费(BitBLAS在Contiguous Batching等场景上确实碰到了这样的问题,为了优化这部分性能不得已去复现这个论文的方法。然而这篇Blog不讲Stream-K的算法与实现细节,也不讲BitBLAS, 而是来分析一下TVM的MergeSharedMemoryAllocations这一个Pass,原因是高效的Stream-K实现需要引入大量的shared memory,而TVM中负责进行Liveness分析来合并shared memory访存的这个Pass,在复杂场景下存在BUG,导致shared memory的复用达不到预期,阻止了我们探索更大的tile size. 为此不得不对这个Pass进行一下改进,本文记录一下对这个Pass的分析和修改,以及我相信大部分TVM的用户在Hack TVM的代码的时候都会头秃,穿插一些TVM的设计和调试经验)
tvm storage align
回答知乎提问:https://www.zhihu.com/question/565420155
最近正好研究了一下这个schedule,顺便简单总结一下,官方给的文档介绍确实比较抽象: https://tvm.apache.org/docs/reference/api/python/tir.html
题主困惑的应该是factor和offset是什么意思,为什么这样能够解决shared memory bank conflict?
第一个问题,可以看看代码,首先是底层的实现(https://github.com/apache/tvm/blob/HEAD/src/tir/transforms/storage_flatten.cc#L480-L481):
1 | |