回答知乎提问:https://www.zhihu.com/question/565420155
最近正好研究了一下这个schedule,顺便简单总结一下,官方给的文档介绍确实比较抽象: https://tvm.apache.org/docs/reference/api/python/tir.html
题主困惑的应该是factor和offset是什么意思,为什么这样能够解决shared memory bank conflict?
第一个问题,可以看看代码,首先是底层的实现(https://github.com/apache/tvm/blob/HEAD/src/tir/transforms/storage_flatten.cc#L480-L481):
1 | |
显然可以通过图中的公式计算出最后的stride,例如网上能搜到的一个case:
1 | |
用这个公式计算一下:
$$
(100+8-1024%100)% 100 + 1024 = (108-24) + 1024 = 1108
$$
这个公式可以理解为,对于原来给定的一个stride,如1024,首先跟factor对其,如1024对其之后是1100,再补上offset,可以实现一个类似memory zero padding的效果,再tvm的repo里,还可以翻到一些经常用的(并没有,奇怪的用法:
1 | |
推导一下公式
$$
stride = stride + (C-1+C-(stride%(C-1)))% (C-1)
$$
而在一些情况下, 这里的CS_align等于stride,则stride不变,如果加上一个offset,则需要另外考虑。
第二个问题需要了解一下在gpu矩阵乘法计算中的一种通过加pad的方式解决bank conflict的方法,假设我们都按照cutlass的思路来进行矩阵乘法计算,并且利用tensorcore,以一个简单的warp算m16n16k16的矩阵乘法为例子:
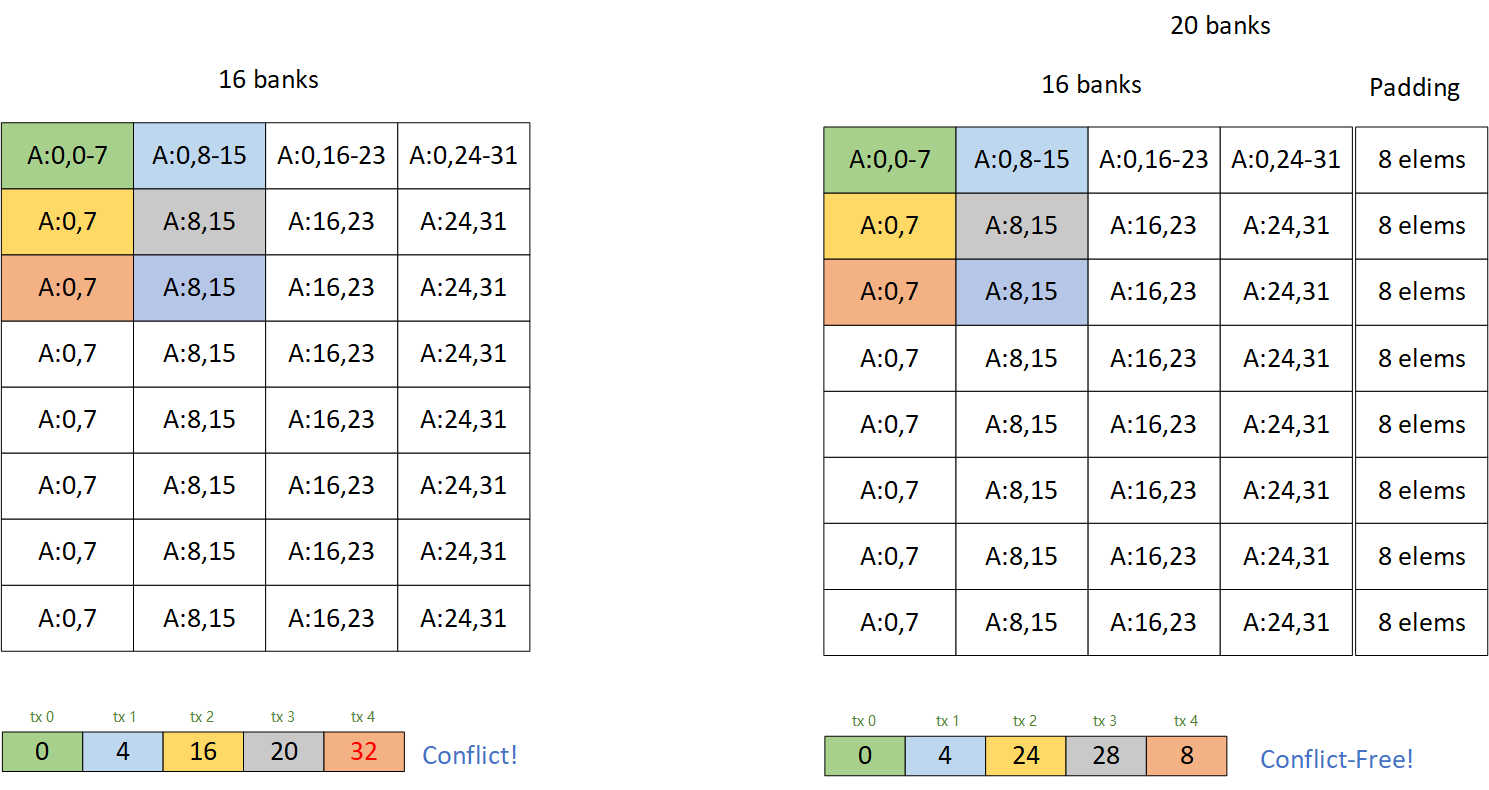
左边图片中白色的部分是一个典型的A矩阵在shared memory里的排布,大小是128*32的矩阵,一次取一个小矩阵在内存的排布,一次使用l ds128指令取八个float16的元素,每个线程访问的bank如下面所示,有一半的bank是没有被访问到的,一种常用的解法是给每一行加PAD,例如右图,每一行加4个bank大小的pad,这样带宽就可以利用满,这样做法的优点是简单,但是缺点也很明显,一是写入shared memory就会有conflict,需要动脑消除一下,二是会增加shared memory的开销,有了这个图示,就可以解决第二个问题了。
回到tvm,如果只用一个storage align schedule,速度可能会快一些,这来源于你解决了wmma::load_matrix_sync引入的shared memory load conflict,但是因为从global memory读入shared memory的shared memory store过程中线程与线程之间多了padding,会导致引入store的conflict。
而且理论上存在解,不需要加padding,控制好每个线程访问的bank让他们不conflict,cutlass里提供了这样的一种解法:
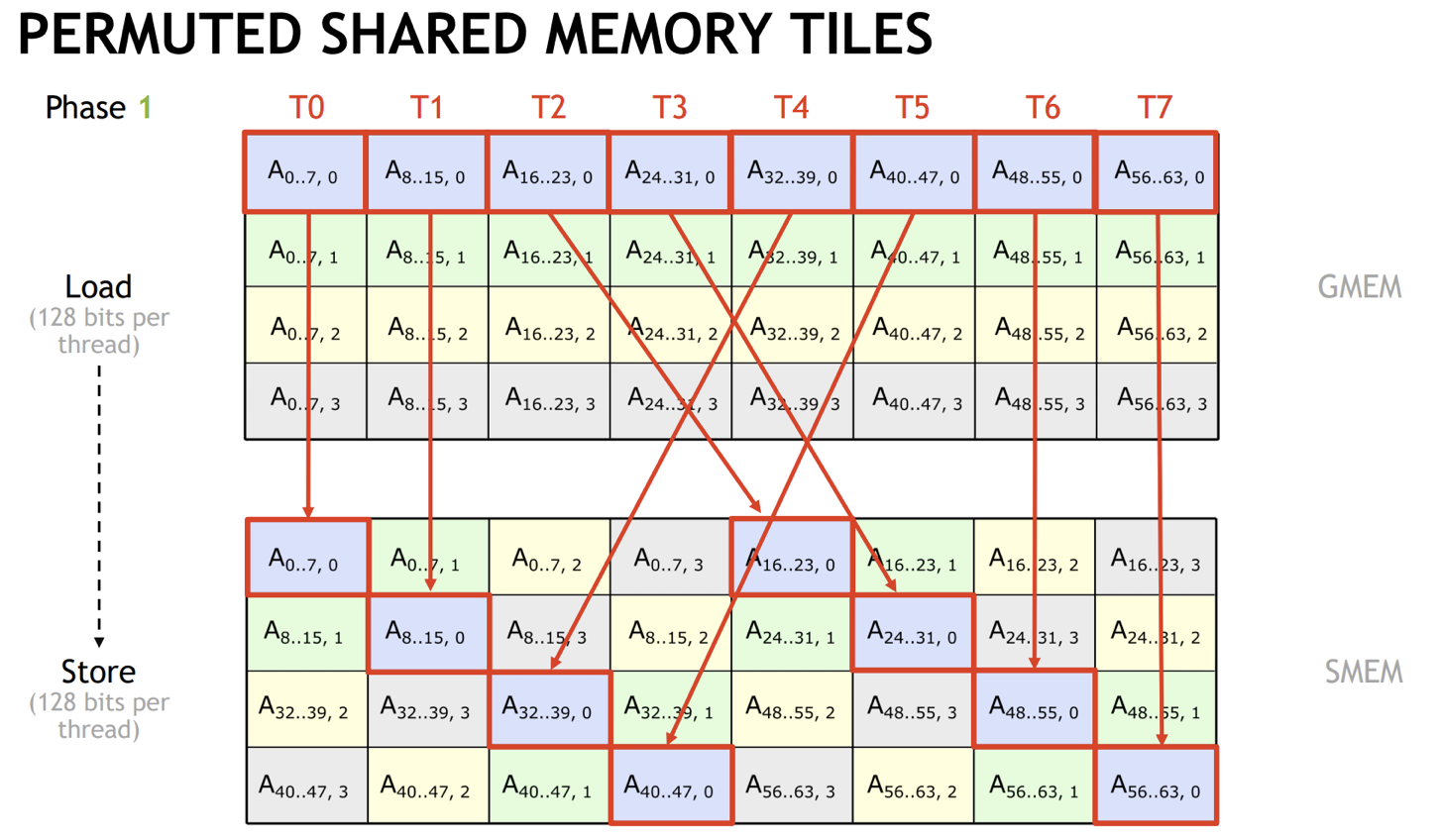
这两种情况显然不能用storage_align解决了,可以用tvm的tensorize schdule和decl_buffer来达到这个目的,这种实现方式也更自由,如这里的代码:
1 | |
1 | |
Comments