
刚开始碰到的问题是这样的:在Azure上开的一台HPC(4块 V100 16G)在运行了大概七八个小时之后,nvidia的显卡会挂掉,具体的表现为nvidia-smi会卡住十几分钟,之后输出No devices were found,但是执行lspci | grep -i nvidia还是可以看到四块显卡好好的挂在上面,这种情况应该直接reboot就可以修复,但是reboot了之后同样的程序运行一段时间之后显卡还是会掉。
刚开始碰到的问题是这样的:在Azure上开的一台HPC(4块 V100 16G)在运行了大概七八个小时之后,nvidia的显卡会挂掉,具体的表现为nvidia-smi会卡住十几分钟,之后输出No devices were found,但是执行lspci | grep -i nvidia还是可以看到四块显卡好好的挂在上面,这种情况应该直接reboot就可以修复,但是reboot了之后同样的程序运行一段时间之后显卡还是会掉。
主要分为三个部分:
Architecture:加速器的体系根据其结构可分为三组,固定数据流的加速器(例如TPU、NVDLA、Eyeriss)、灵活数据流的加速器(例如Eyeriss v2、Maeri、Sigma)和chiplet多核加速器(例如SIMBA)。与包括CPU和GPU在内的传统体系结构不同,空间体系结构使用ScratchPad作为片上buffer。和传统的CPU体系结构里的Cache不一样,ScratchPad是可编程的,数据从DDR往ScracthPad上load的过程是由用户生成指令来操作,因为要取的数据地址相对来讲固定,所以理论上存在一个最有的数据流动序列,详见HPCA19上的《 Communication Lower Bound in Convolution Accelerators 》,而Cache是根据局部性原理由硬件完成这个操作,用户不可控。
Cost Models:也是因为Cache的原因,对加速器运行效率的建模不一定需要使用cycle级别的模拟器就可以。现在开源的就存在着不同的cost模型,用于以不同程度的保真度,为不同类型的加速器建模。例如,SCALE-sim来仿真脉动阵列(TPU), MAESTRO仿真的阵列具有可配置的宽高比,Timeloop在模拟的时候可以考虑到复杂的内存层次结构建模,Tetris可以建模3D阵列。
Mappers:使用Cost Models,可以用目标硬件上的特定的map来估计程序的性能。然而,要为给定的工作负载和体系结构找到最佳映射并不简单,原因有两个。首先,映射的空间可能非常大,这使得穷举搜索变得不可行。这导致了几种映射器的开发,它们通过修剪搜索空间或用有效的方法搜索来减少搜索时间。Marvel提出了一种分离芯片外map空间和片上map空间的方法,timeloop利用了基于采样的搜索方法,Interstella使用了基于启发式的搜索方法,Mind Mapping开发了一个子模型来基于梯度搜索,而Gamma使用了基于遗传算法的方法通过利用先前的结果来有效地推进。其次,定义Map的搜索空间本身通常很复杂,因为不同的操作和不同的硬件加速器可能会对可行的映射施加约束。这就是为什么现在的Mapper在今天高度依赖于特定的成本模型,从而限制了可扩展性。
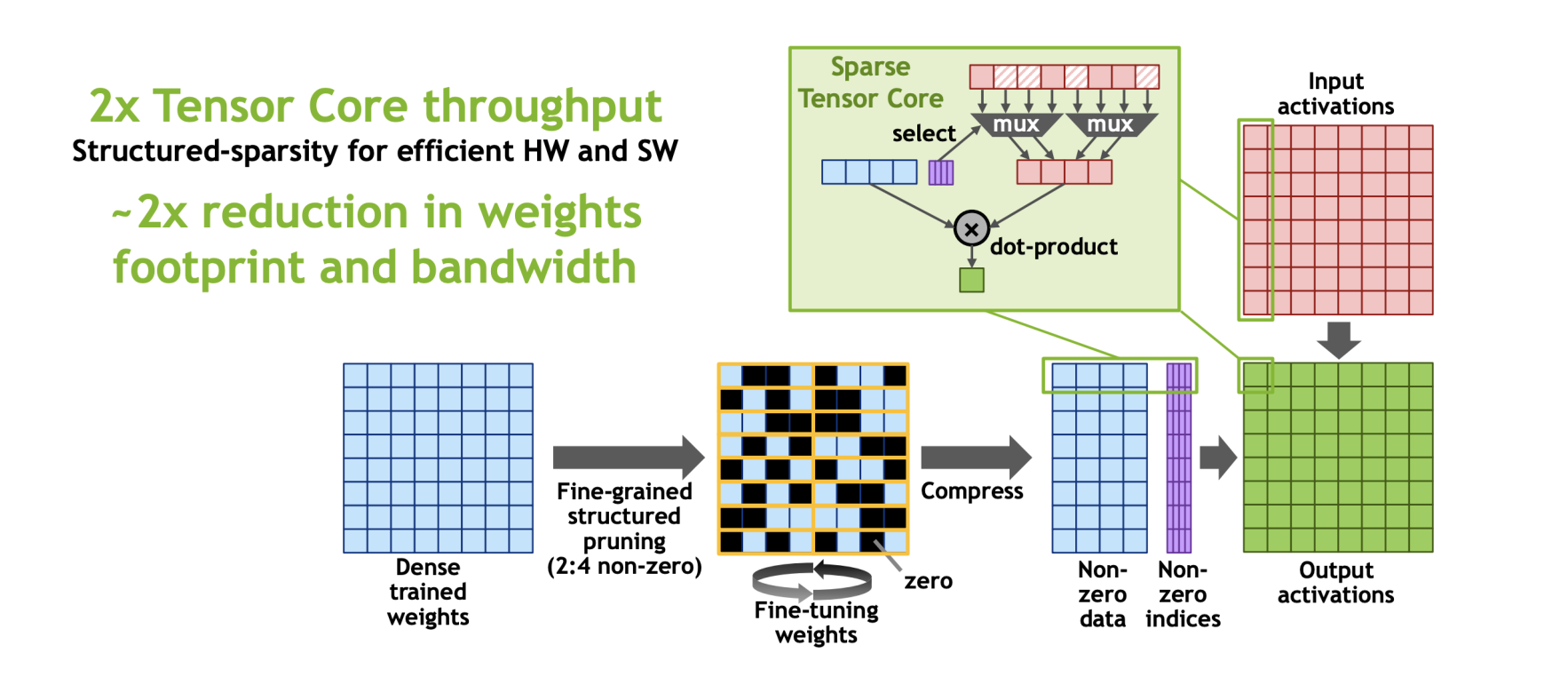
A100卡(Ampere GPU Arch)上的Sparse Tensor Core的稀疏加速用的是类似FPGA19上的这篇《Efficient and Effective Sparse LSTM on FPGA with Bank-Balanced Sparsity》的Bank Sparsity的方法,硬件实现比较简单,而且有利于负载均衡。
简单来讲,在Sparse Tensor Core上,对于W*A,把大矩阵W拆分成很多个1*4的小块,然后强制让稀疏度为50%,即每4个元素,去除掉其中绝对值最小的两个值,这种稀疏压缩方式成为(2:4 bank sarsity),对原本的tensor core也只需要做很小的修改,像下图中加一个mux四个有值的下标来选出与之匹配的矩阵A中的元素进行运算。
《LLHD: A Multi-level Intermediate Representation for Hardware Description Languages》
因为在CIRCT里有一个叫llhd的dialect,于是很简单的survey了一下这个工作,这篇是苏黎世联邦理工学院发表在PLDI 2020上的,借助MLIR的设计思想,想在EDA领域设计一个统一的IR。
MLIR 是Google在2019年开源出来的编译框架。不久之前意外加了nihui大佬建的MLIR交流群,不过几个月过去了群里都没什么人说话,说明没人用MLIR(不是。现在刚好组里的老师对MLIR比较感兴趣让我进行一下调研,于是就有这篇比较简单的调研报告啦!
MLIR的全称是 Multi-Level Intermediate Representation. 其中的ML不是指Machine Learning,这一点容易让人误解,但现在的一些ML框架有些也在往MLIR靠,比如Tensorflow、Pytorch、ONNX都在写Dialect往MLIR上贴贴,Google的IREE是基于MLIR的End2End推理框架;ML也可以是Mid-Level,因为MLIR要解决Mid-Level IR的碎片化问题;ML也可以是摩尔定律,因为MLIR的Paper的标题是为了摩尔定律终结而诞生的编译器技术设施,当然也可以是Modular Library,现在看来,MLIR至少是一个优秀的编译器库。
一些你可以帮助你了解MLIR的资源:
目前,MLIR已经迁移到了LLVM下面进行维护。
如果想要引用MLIR,使用这一篇Paper:MLIR: A Compiler Infrastructure for the End of Moore’s Law
MLIR SIG 组每周都会有一次 public meeting,如果你有特定的主题想讨论或者有疑问,可以根据官网主页提供的方法在他们的文档里提出,有关如何加入会议的详细信息,请参阅官方网站上的文档。
Update your browser to view this website correctly. Update my browser now