
刚开始碰到的问题是这样的:在Azure上开的一台HPC(4块 V100 16G)在运行了大概七八个小时之后,nvidia的显卡会挂掉,具体的表现为nvidia-smi会卡住十几分钟,之后输出No devices were found,但是执行lspci | grep -i nvidia还是可以看到四块显卡好好的挂在上面,这种情况应该直接reboot就可以修复,但是reboot了之后同样的程序运行一段时间之后显卡还是会掉。
刚开始碰到的问题是这样的:在Azure上开的一台HPC(4块 V100 16G)在运行了大概七八个小时之后,nvidia的显卡会挂掉,具体的表现为nvidia-smi会卡住十几分钟,之后输出No devices were found,但是执行lspci | grep -i nvidia还是可以看到四块显卡好好的挂在上面,这种情况应该直接reboot就可以修复,但是reboot了之后同样的程序运行一段时间之后显卡还是会掉。
主要分为三个部分:
Architecture:加速器的体系根据其结构可分为三组,固定数据流的加速器(例如TPU、NVDLA、Eyeriss)、灵活数据流的加速器(例如Eyeriss v2、Maeri、Sigma)和chiplet多核加速器(例如SIMBA)。与包括CPU和GPU在内的传统体系结构不同,空间体系结构使用ScratchPad作为片上buffer。和传统的CPU体系结构里的Cache不一样,ScratchPad是可编程的,数据从DDR往ScracthPad上load的过程是由用户生成指令来操作,因为要取的数据地址相对来讲固定,所以理论上存在一个最有的数据流动序列,详见HPCA19上的《 Communication Lower Bound in Convolution Accelerators 》,而Cache是根据局部性原理由硬件完成这个操作,用户不可控。
Cost Models:也是因为Cache的原因,对加速器运行效率的建模不一定需要使用cycle级别的模拟器就可以。现在开源的就存在着不同的cost模型,用于以不同程度的保真度,为不同类型的加速器建模。例如,SCALE-sim来仿真脉动阵列(TPU), MAESTRO仿真的阵列具有可配置的宽高比,Timeloop在模拟的时候可以考虑到复杂的内存层次结构建模,Tetris可以建模3D阵列。
Mappers:使用Cost Models,可以用目标硬件上的特定的map来估计程序的性能。然而,要为给定的工作负载和体系结构找到最佳映射并不简单,原因有两个。首先,映射的空间可能非常大,这使得穷举搜索变得不可行。这导致了几种映射器的开发,它们通过修剪搜索空间或用有效的方法搜索来减少搜索时间。Marvel提出了一种分离芯片外map空间和片上map空间的方法,timeloop利用了基于采样的搜索方法,Interstella使用了基于启发式的搜索方法,Mind Mapping开发了一个子模型来基于梯度搜索,而Gamma使用了基于遗传算法的方法通过利用先前的结果来有效地推进。其次,定义Map的搜索空间本身通常很复杂,因为不同的操作和不同的硬件加速器可能会对可行的映射施加约束。这就是为什么现在的Mapper在今天高度依赖于特定的成本模型,从而限制了可扩展性。
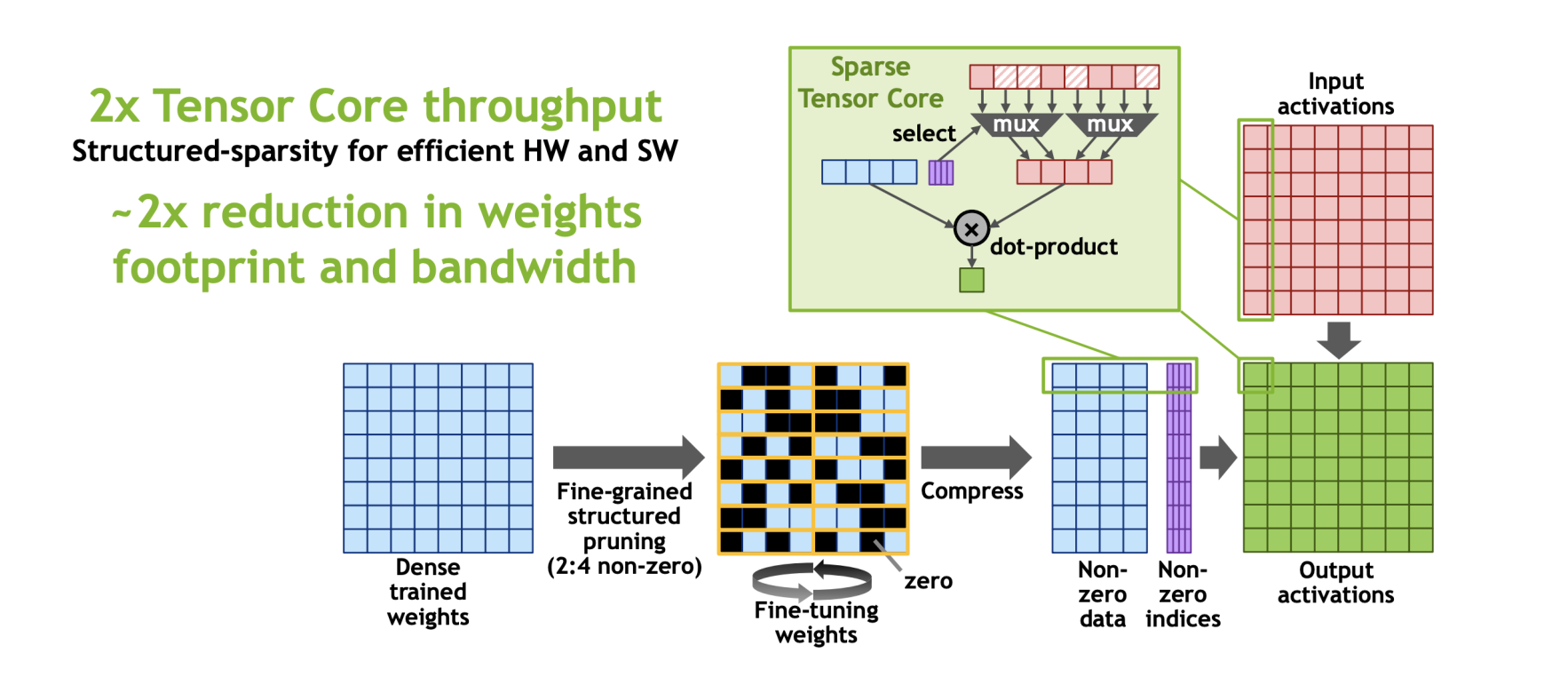
A100卡(Ampere GPU Arch)上的Sparse Tensor Core的稀疏加速用的是类似FPGA19上的这篇《Efficient and Effective Sparse LSTM on FPGA with Bank-Balanced Sparsity》的Bank Sparsity的方法,硬件实现比较简单,而且有利于负载均衡。
简单来讲,在Sparse Tensor Core上,对于W*A,把大矩阵W拆分成很多个1*4的小块,然后强制让稀疏度为50%,即每4个元素,去除掉其中绝对值最小的两个值,这种稀疏压缩方式成为(2:4 bank sarsity),对原本的tensor core也只需要做很小的修改,像下图中加一个mux四个有值的下标来选出与之匹配的矩阵A中的元素进行运算。
how-to-optimiza-gemm 是大家参考得比较多的gemm优化tutorial,本文是在我的MacBook Pro 2019上进行的实践,处理器型号是i5-8257U.
代码在:https://github.com/LeiWang1999/optimize-gemm-on-macbook2019
从来没见过语法像CMake这么烂的DSL,构建项目的时候总是要去查文档,但是查了文档还是不知道该怎么办💢,这里记一下自己常用的一些写法。
近些日子在看看图神经网络这种非常稀疏的网络运算系统中有没有什么自己可以做的编译优化,其实在编译现在主流的图神经网络训练框架DGL的时候就不难注意到其依赖项里是有TVM的,这是不是说明现在的DGL也在使用TVM来进行自动调优呢?带着这个疑问我翻了一下DGL的代码,发现和tvm有关的部分只有一个叫做FeatGraph的框架,顺藤摸瓜找到了胡玉炜大佬发表在SC20上的Paper:
《FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems》
在2021年6月亚马逊云科技 Community Day 上,张建老师做的题为《图神经网络和DGL在实际落地项目中的挑战和思考》这个Talk里指出,现在主流的图神经网络框架DGL的自己裁剪的Gunrock之后制作的minigun来做运算加速的,但是根据代码大胆猜测一下实际上DGL只在在0.3~0.4中才有使用的是minigun来做一些加速,在0.5中就不使用minugun了,而是将主要的运算抽象成了SpMM(稀疏稠密的矩阵乘)和SDDMM(sampled稠密稠密矩阵乘)两种运算,这项工作在DGL达到版本0.6的时候结合tvm的高效代码生成转变为了FeatGraph发表在SC20上,而现在DGL已经前进到了0.7版本了。
Update your browser to view this website correctly. Update my browser now